Scraping Amazon With Python: Step-By-Step Guide
TLDRThis script offers a comprehensive guide on efficiently extracting Amazon product data using web scraping techniques. It outlines the necessary steps, including setting up a Python environment, installing required libraries like Requests and Beautiful Soup, and crafting code to navigate and scrape product details from Amazon's category and product detail pages. The guide also emphasizes the importance of adhering to best practices to avoid detection and blocking by Amazon, such as using realistic user agents and consistent fingerprints. Additionally, it introduces Amazon Scraper API as a ready-made solution for scraping Amazon data in JSON format without the need for additional libraries.
Takeaways
- 🔧 To extract Amazon product data efficiently, one should use a reliable web scraper and Python programming language.
- 💻 Before starting, install Python 3.8 or above from python.org and create a virtual environment for the project.
- 📦 Install required Python packages like 'requests' for making HTTP requests and 'beautifulsoup' for parsing HTML and XML files.
- 🛠️ To bypass Amazon's blocking mechanism, send headers along with your request, mimicking those sent by a web browser.
- 🔍 Amazon product data can be found on two types of pages: the category page, which lists products, and the product details page, which provides in-depth information.
- 🌐 Use CSS selectors with Beautiful Soup to extract specific elements like product titles, prices, images, and descriptions from the product details page.
- 📊 For scraping product reviews, collect all review objects and extract individual pieces of information such as author names, ratings, titles, review texts, and dates.
- 🔄 Handle pagination by finding the link to the next page and parsing the relative URLs to continue scraping through multiple pages.
- 🚫 Be aware of Amazon's rate limiting and detection algorithms; adapt your scraping techniques to avoid getting blocked.
- 📈 Follow best practices such as using a real user agent, setting consistent fingerprint parameters, and changing crawling patterns to mimic regular user behavior.
- 🎯 Alternatively, use a pre-built scraping solution like Amazon Scraper API, which can parse various Amazon page types and return data in JSON format without the need for additional libraries.
Q & A
What is the primary purpose of building a web scraper for Amazon as discussed in the script?
-The primary purpose of building a web scraper for Amazon is to efficiently extract product data, which can be useful for monitoring the performance of products sold by third-party resellers or tracking competitors.
Which version of Python is recommended to use for this web scraping project?
-Python 3.8 or above is recommended for this web scraping project.
What is the significance of creating a virtual environment for the web scraping project?
-Creating a virtual environment is a good practice as it helps to manage project dependencies and keeps them isolated from other projects, avoiding potential conflicts.
What are the two main Python libraries required for web scraping as per the script?
-The two main Python libraries required for web scraping as per the script are 'requests' for making HTTP requests and 'BeautifulSoup' for parsing HTML and XML files.
Why does Amazon block certain requests and what is the common error code received?
-Amazon blocks requests that it identifies as not coming from a browser. The common error code received in such cases is 503, which indicates a server error.
How can you mimic a browser request to avoid being blocked by Amazon?
-You can mimic a browser request by sending headers along with your request that a browser would typically send. Sometimes, sending only the user agent is enough, but other times you may need to send more headers, such as the accept-language header.
What are the two categories of pages you would typically work with when scraping Amazon products?
-When scraping Amazon products, you would typically work with two categories of pages: the category page, which displays search results, and the product details page, which provides more detailed information about a specific product.
How can you extract the product title from a product details page using BeautifulSoup?
-You can extract the product title from a product details page using BeautifulSoup by using a CSS selector that targets a span element with its ID attribute set to 'productTitle'.
What is the recommended approach to handle pagination when scraping Amazon product listings?
-To handle pagination when scraping Amazon product listings, you can look for the link containing the text 'next' using a CSS selector and extract the URL for the next page from it. Note that the links will be relative, so you would need to use the URL join method to parse these links.
What are some best practices to prevent getting detected and blocked by Amazon while scraping?
-Some best practices include using a real user agent, setting consistent fingerprint parameters to avoid IP fingerprinting, and changing the crawling pattern to mimic regular user behavior with clicks, scrolls, and mouse movements.
How can you utilize Amazon Scraper API for web scraping Amazon product data?
-Amazon Scraper API is a ready-made solution for scraping Amazon product data. It allows you to scrape and parse various Amazon page types, including search results, product listings, reviews, and more, in JSON format without the need to install any additional libraries.
What is the process for extracting product reviews from an Amazon product page?
-To extract product reviews from an Amazon product page, you first need to find all the review objects using a CSS selector, then iterate through them to collect the required information such as the author's name, rating, title, review text, and date. The 'verified' status of the review can also be extracted if needed.
Outlines
🔧 Setting Up Your Web Scraping Environment
This paragraph discusses the initial setup for web scraping Amazon product data. It emphasizes the need for Python 3.8 or higher and the creation of a folder to store web scraping code files. The concept of a virtual environment is introduced, with specific commands provided for Mac OS and Linux, and slightly varied commands for Windows. The paragraph also outlines the installation of essential Python packages for HTTP requests and HTML parsing, namely 'requests' and 'beautiful soup'. The importance of using headers to mimic browser requests and bypass Amazon's blocking mechanisms is highlighted. Additionally, the text touches on the common practice of Amazon blocking non-browser requests and the use of tools like 'playwright' or 'selenium' for JavaScript rendering.
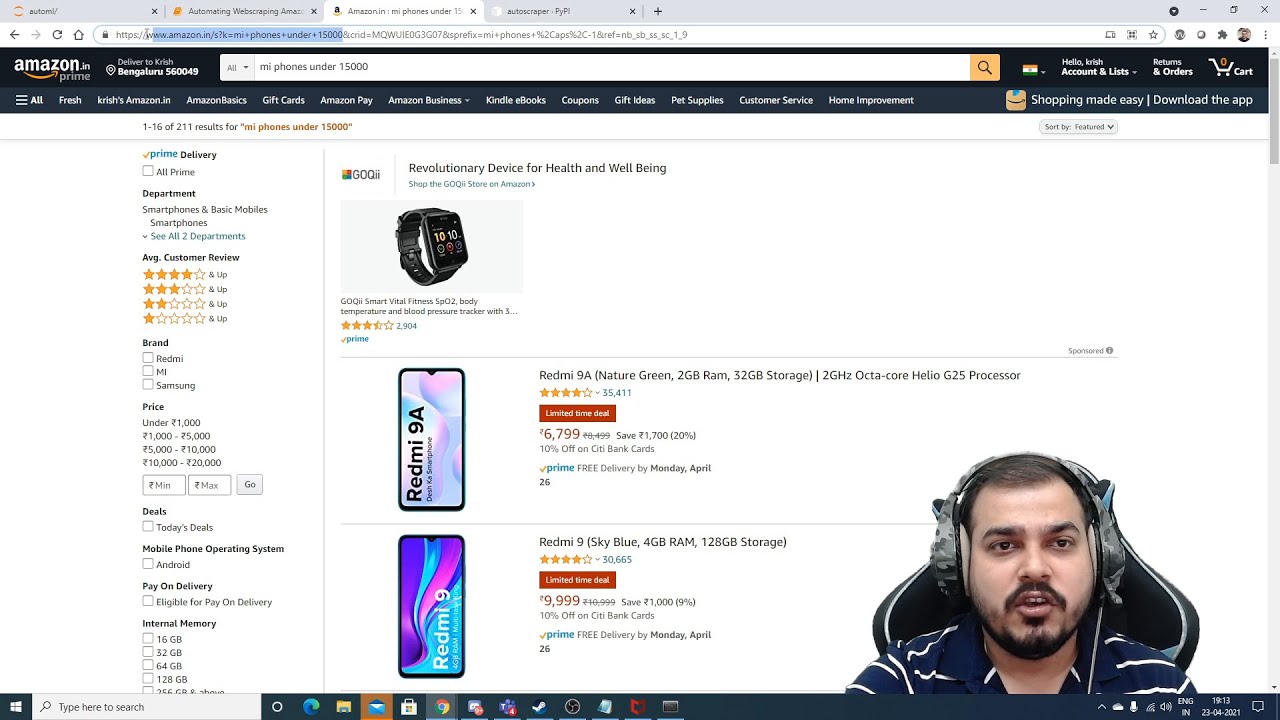
🔍 Understanding Amazon Product Page Structure
This paragraph delves into the structure of Amazon product pages, distinguishing between category pages, which display search results with product titles, images, ratings, and prices, and product detail pages, which offer more comprehensive information like descriptions. It explains how to inspect elements on a product detail page, such as the title, price, rating, and image, using browser developer tools. The paragraph introduces the use of 'beautiful soup' for extracting data from these elements using CSS selectors and methods. It also covers the process of locating and scraping additional details like product descriptions and reviews, noting the complexity involved in handling review data due to the potential volume and variety of information.
📋 Extracting and Processing Review Data
This section focuses on the extraction and processing of review data from Amazon product pages. It describes how to identify and collect all review objects using CSS selectors and iterate through them to gather necessary information. The process involves extracting the reviewer's name, rating, title, review text, and date, as well as verifying the review. The paragraph explains how to assemble the extracted information into a single object and add it to a collection of processed reviews. It also touches on the challenges of scraping product reviews due to the potential abundance of data and the complexity of review content.
🌐 Navigating Amazon Categories and Pagination
This paragraph explains how to navigate Amazon's category pages and handle pagination. It describes how products are contained within a specific div and how to use the 'data-asin' attribute to extract product links. The text also covers the creation of a loop to process these links and the necessity of converting relative links into full URLs. Furthermore, it discusses strategies for handling pagination, such as identifying the 'next' page link using CSS selectors and the importance of adapting to different page layouts and HTML structures. The paragraph concludes with a brief mention of best practices for scraping Amazon, including using a real user agent, setting a consistent fingerprint, and developing a natural crawling pattern to avoid detection and blocking.
🚀 Utilizing Amazon Scraper API for Efficient Data Extraction
This paragraph introduces the Amazon Scraper API as an efficient solution for extracting Amazon product data. It highlights the ability to retrieve accurate and parsed results in JSON format without the need for additional libraries. The text emphasizes the API's capability to handle localized product data across 195 locations worldwide. It outlines the ease of using the API for extracting details from product pages and searching for products, regardless of the Amazon domain. The paragraph concludes by inviting users to share their preferences between building their own scraper or using ready-made solutions like the Amazon Scraper API.
Mindmap
Keywords
💡Web Scraping
💡Python
💡Virtual Environment
💡Requests Library
💡Beautiful Soup
💡User Agent
💡Category Page
💡Product Details Page
💡CSS Selectors
💡Pagination
💡Best Practices
Highlights
Building a reliable web scraper for Amazon product data is essential for monitoring performance of products sold by third-party resellers or tracking competitors.
Python 3.8 or above is required for web scraping, and a virtual environment is recommended for isolating the project dependencies.
The 'requests' library is a popular Python library for making HTTP requests, providing an intuitive interface to interact with web servers.
Beautiful Soup is a Python library used for web scraping, allowing the extraction of information from HTML and XML files by searching for tags, attributes, or specific text.
Amazon may block requests that do not use a browser, but this can be mitigated by sending headers along with the request, such as the user agent and accept language headers.
Web scraping Amazon involves working with two categories of pages: the category page, which displays search results, and the product details page, which provides more detailed information.
The structure of the product details page can be examined by right-clicking on elements like the product title or price and selecting 'Inspect' to view the HTML markup.
Beautiful Soup supports unique methods and CSS selectors for selecting tags, which can be utilized to extract specific information like product names, ratings, and prices.
Scraping Amazon product reviews involves extracting various pieces of information, such as the author's name, rating, title, review text, and the date of the review.
To navigate Amazon category pages, a CSS selector can be used to read the 'data-asin' attribute from a div containing all product links, which are relative and need to be parsed using the URL join method.
Handling pagination on Amazon involves finding the link to the next page using a CSS selector that targets links containing the text 'next'.
Scraped data from Amazon is returned as a dictionary and can be used to create a pandas DataFrame for further analysis and processing.
Best practices for scraping Amazon include using a real user agent, setting a consistent fingerprint to avoid detection, and changing the crawling pattern to mimic regular user behavior.
Amazon Scraper API is a ready-made solution for scraping Amazon, which can parse various page types, including search results, product listings, reviews, and best sellers, in JSON format without the need for additional libraries.
The Amazon Scraper API can extract complete product data from a single URL, irrespective of the Amazon store's country, demonstrating its versatility and ease of use.
Searching for products on Amazon using the Scraper API is straightforward, with the ability to limit the search to specific categories and number of pages for targeted results.
Transcripts
Browse More Related Video

Web Scraping with Python and BeautifulSoup is THIS easy!

Amazon Web Scraping Using Python | Data Analyst Portfolio Project
Automating WebScraping Amazon Ecommerce Website Using AutoScrapper

Web Scraping with ChatGPT is mind blowing 🤯

How To Scrape Websites With ChatGPT (As A Complete Beginner)

ParseHub Tutorial: Scraping 2 eCommerce Websites in 1 Project
5.0 / 5 (0 votes)
Thanks for rating: