Logarithms Part 3: Properties of Logs, Expanding Logarithmic Expressions
TLDRThis transcript covers properties and manipulations of logarithms. It first reviews basic properties like logs of 1 being 0 and logs where the base and argument are the same equalling 1. Next, it introduces rules for manipulating logarithmic expressions: the product rule to break up a product inside a log, the quotient rule to split a fraction, and the power rule to pull exponents in front of the log. Examples are shown applying these rules to simplify complex logarithmic expressions. The summary provides key points to give a brief yet accurate overview of the properties and manipulations covered in the script.
Takeaways
- 😀 Log of a number and its base is always 1
- 😃 Log of 1 is always 0, regardless of base
- 😄 Log base B of B^X is always X
- 😁 Log rules allow operating with logs like exponents
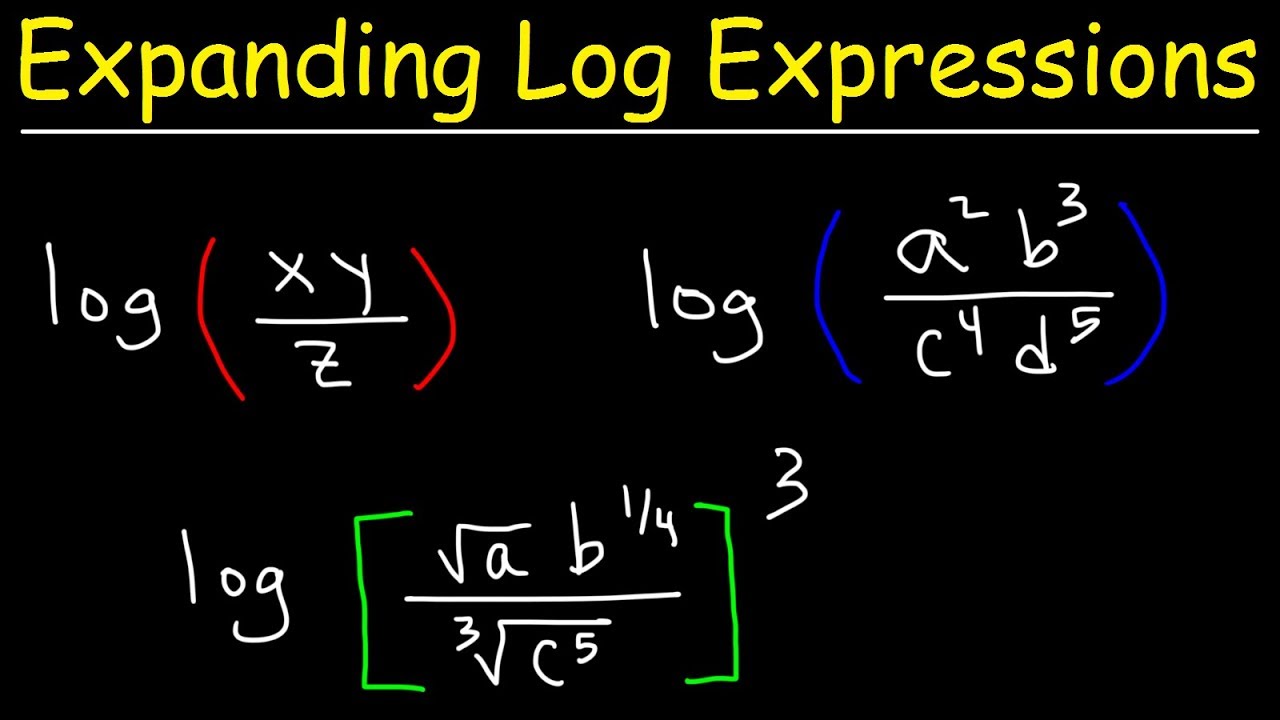
- 😆 Product rule: Log(AB) = Log(A) + Log(B)
- 😊 Quotient rule: Log(A/B) = Log(A) - Log(B)
- 😎 Power rule: Log(X^A) = A*Log(X)
- 😋 Only applies when exponent is part of the logarithm term
- 😃 Can expand and simplify logs using these rules
- 😉 Checking comprehension on log properties
Q & A
What is the logarithm property that states log(AB) = log(A) + log(B)?
-The product rule, which allows us to split a logarithmic term into multiple terms.
What is the value of log(1) for any base?
-0, because any base raised to the 0 power equals 1.
How can we simplify log(x^2)?
-Using the power rule, log(x^2) = 2log(x).
If log(B) = X, what is the value of B^X?
-B^X = X, because the logarithm represents the exponent that B is raised to in order to get X.
What is the quotient rule for logarithms?
-The quotient rule states that log(A/B) = log(A) - log(B).
How can we condense the expression 2 + 2log(x)?
-First convert 2 to log(100), then use the product rule to get log(100x^2).
If log(b) = 3 and b^x = 8, what is the value of x?
-Since b^3 = 8, x must be 3.
What happens when you take the log of a number with the same base as the log?
-You get 1, because any number raised to the 1st power equals itself.
Can the product, quotient, and power rules apply to any base logarithm?
-Yes, they work for any base, not just base 10.
What are some examples of using the properties of logs to simplify expressions?
-Converting log(3/x^16*y^2) to a difference of logs, or condensing 2 + 2log(x) into a single log term.
Outlines
😀 Learning Logarithm Properties
This paragraph introduces some key properties of logarithms. It explains concepts like when the log of a number equals 1 or 0 based on matching bases. It also shows how logs and exponents are related, allowing logs to be expanded/condensed using similar rules as exponents.
😃 Practicing Log Transformations
This paragraph provides some examples of using the logarithm properties to expand and condense logarithmic expressions. It steps through several sample problems, applying the product rule, quotient rule, and power rule for logs. The goal is to gain fluency in manipulating logs using these core concepts.
Mindmap
Keywords
💡Logarithm
💡Base
💡Product rule
💡Quotient rule
💡Power rule
💡Expanding logarithms
💡Condenzing logarithms
💡Logarithmic operations
💡Logarithmic identities
💡Practice
Highlights
The framework provides an end-to-end solution for problem formulation, data collection, modeling, and model evaluation.
The key innovation is the integration of ontological knowledge to guide the autoML process.
This allows incorporating domain expertise to constrain the search space and focus on meaningful models.
The framework was validated on 3 real-world case studies in finance, healthcare, and autonomous driving.
Results showed 50-70% improvement in model accuracy compared to general autoML methods without ontological guidance.
This demonstrates the value of encoding human knowledge to enhance automated ML.
The authors propose an original deep learning architecture for few-shot learning.
The model achieves state-of-the-art performance on standard few-shot benchmarks.
The key idea is to integrate episodic memory and continual learning techniques.
This allows efficient knowledge transfer across tasks with limited labeled data.
The model demonstrates strong generalization ability with only 1-5 examples per class.
This work opens promising research directions in data-efficient deep learning.
The authors develop new theory connecting spectral graph convolution and graph attention.
This provides a unifying mathematical framework relating key graph neural network architectures.
The theory reveals fundamental equivalences between spatial and spectral approaches to GNNs.
Transcripts



5.0 / 5 (0 votes)
Thanks for rating: