ParseHub Tutorial: Scraping Product Details from Amazon
TLDRThis tutorial showcases a step-by-step guide on using a web scraping tool called Parcel to extract product details from an e-commerce website. It walks users through the process of setting up a project, selecting and extracting data from product pages, and handling pagination. The guide also explains how to create and apply templates for different page layouts, use relative selection commands to relate data, and test the scraping process. The tutorial aims to help users efficiently gather e-commerce data for analysis or other purposes.
Takeaways
- 🌐 Start by opening the PriceUp client and creating a new project with the target e-commerce website's URL.
- 🔍 The Parcel client interface consists of three sections: commands and settings on the left, the interactive website view in the middle, and data preview at the bottom.
- 📈 Scroll down the website to load more products and observe how Parcel highlights and lists them for data scraping.
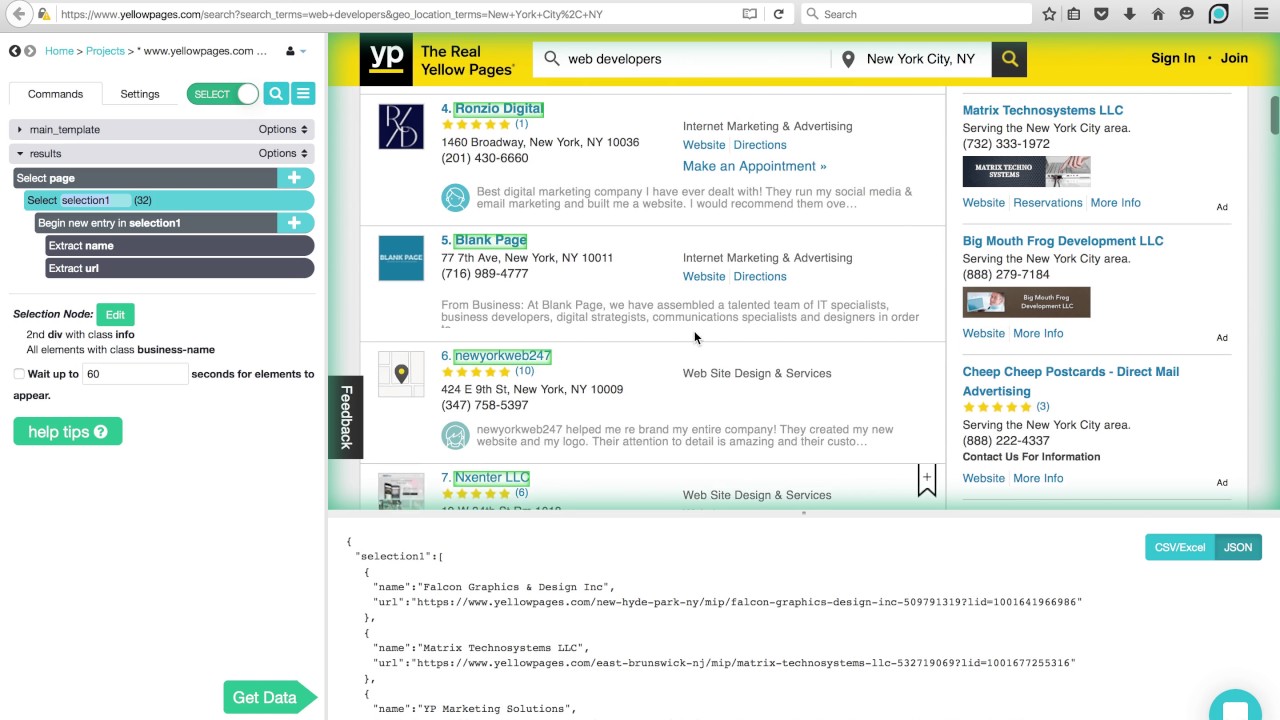
- 🔹 Use the selection command to interact with and select elements on the website, such as product titles.
- 🟩 Parcel highlights similar elements on the page, allowing for batch selection of data points like multiple book titles.
- 📝 Utilize relative select commands to relate and extract additional data from the selected product, such as the author's name and price.
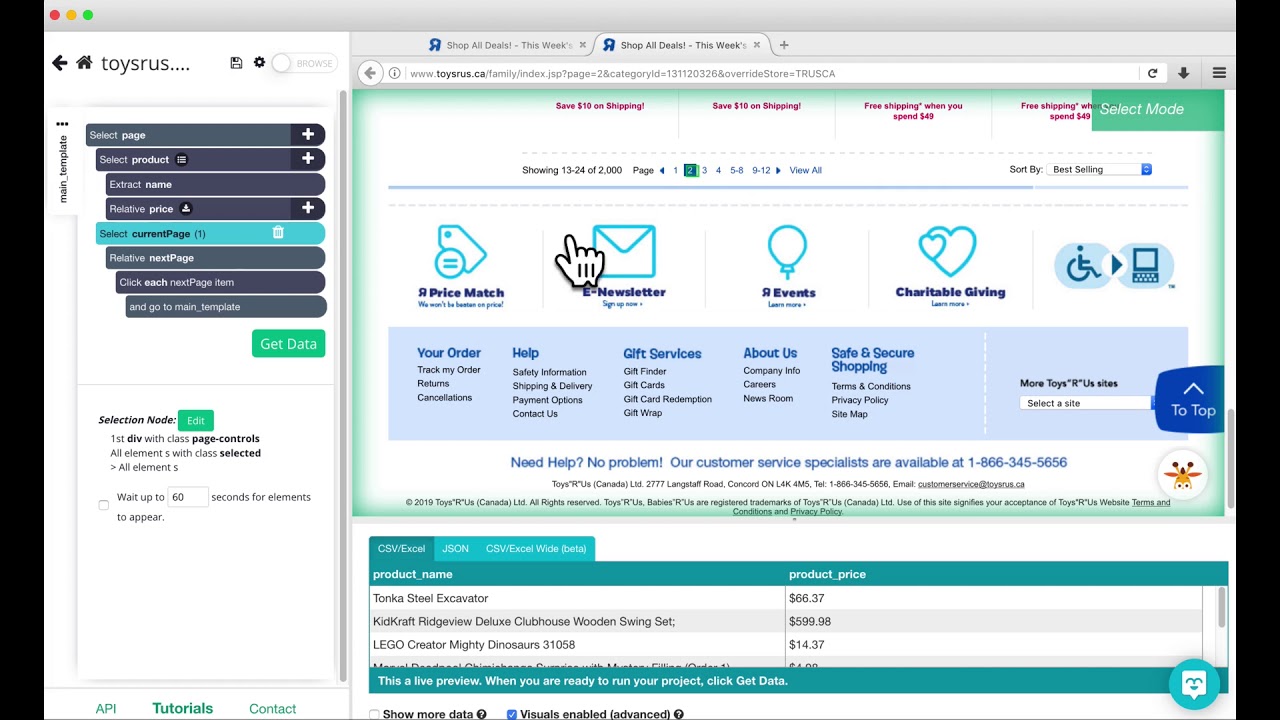
- 🔄 For pagination, use the 'Next' button selection and apply the existing template to replicate the data scraping process across all pages.
- 🔍 Click into individual products to access their detail pages and create new templates for different layout structures.
- 📋 On product detail pages, use select commands to extract specific data points like price, number of reviews, and product dimensions.
- 🔍 Use conditional commands to filter and extract data based on specific criteria, such as labels containing certain words.
- 🚀 Test run the project locally to ensure the scraping process is working as expected and make adjustments if necessary.
- 📊 Once satisfied, run and save the project to collect data in CSV or JSON format, or use the provided API for integration with other applications.
Q & A
What is the first step in using ParseHub to scrape an e-commerce website?
-The first step is to open the ParseHub client, click on 'New Project', and enter the URL of the website you wish to scrape data from.
How does ParseHub allow you to select and preview data on the website?
-ParseHub divides the interface into three areas: commands and settings on the left, an interactive view of the website in the middle, and a data preview section at the bottom where you can view your data in CSV or JSON format.
How can you select all products on multiple pages of an e-commerce website?
-By using a 'Select' command to click on the first product title, then using 'Relative Select' commands to relate and select additional data from each product page, and finally using a 'Select Page' command to navigate through all pages.
What does the 'Relative Select' command do in ParseHub?
-The 'Relative Select' command is used to relate and extract data from elements that are in proximity to the initially selected element, such as selecting the author's name and price from the product title.
How can you customize the extracted data in ParseHub?
-You can customize the extracted data by renaming selection commands to more descriptive terms, using 'Extract' commands to choose specific data types like text or URL, and applying conditions to select data based on certain criteria.
What is a 'Conditional' command in ParseHub and how is it used?
-A 'Conditional' command is used to check if a specific condition is met, such as if a label contains a certain word. If the condition is met, it triggers an action like extracting data that appears next to the label.
How do you test your ParseHub project to ensure it works as expected?
-You can test your project by clicking on 'Test Run' in the menu, which allows you to run the project locally on your computer and observe its behavior step by step or up to five pages at a faster speed.
What options are available for collecting and saving the scraped data in ParseHub?
-After the project has finished running, you can collect your data in formats such as CSV or JSON, and ParseHub also offers an API for integrating your data into other applications.
How can you handle situations where data is not consistently ordered on different pages?
-You can use 'Select' commands to individually select and extract data from different sections of the page, and in cases where the order varies, you can instruct ParseHub to look through all possible titles and select the one with the required information.
What is the purpose of the 'Advanced' options in ParseHub commands?
-The 'Advanced' options allow for more detailed customization of commands, such as specifying exact text extraction or applying conditions to 'Conditional' commands for more precise data selection.
How can you navigate through an e-commerce website to scrape all products on multiple pages?
-By using a 'Select Page' command to select the 'Next' button and applying a 'Click' command to it, which allows ParseHub to navigate through all pages and continue scraping data.
Outlines
🌐 Introduction to Web Scraping with Parcel
This paragraph introduces viewers to a tutorial on web scraping using the Parcel tool. It outlines the initial steps of starting a new project in Parcel, selecting a target website (e.g., Amazon's literature and fiction category), and navigating the interface to scrape product details. The explanation includes how to interact with the Parcel client, interpret the interactive view, and preview data in CSV or JSON format. The paragraph emphasizes the process of selecting products on multiple pages and obtaining more information from each product page.
🔍 Selecting and Extracting Product Data
The second paragraph delves into the specifics of selecting and extracting product data from a webpage. It describes how to use selection commands to identify and gather information such as product names, author names, and publication dates. The tutorial demonstrates the use of relative select commands to relate data and the process of creating a new template for product pages with different layouts. It also addresses the challenge of selecting data that does not follow a consistent order by using conditional commands to filter and extract the desired information.
🚀 Running and Testing the Web Scraping Project
The final paragraph focuses on running and testing the web scraping project. It explains how to execute a test run of the project locally to observe its behavior and make necessary adjustments. The paragraph also covers how to run the project on Parcel's servers and collect the scraped data in CSV or JSON format. Additionally, it mentions the availability of an API for integrating the scraped data into other applications. The tutorial concludes by encouraging users to seek help from the support team if they encounter any issues with their projects.
Mindmap
Keywords
💡e-commerce website
💡scrape
💡parcel
💡interactive view
💡data preview
💡selection command
💡relative select command
💡extract command
💡conditional command
💡template
💡test run
Highlights
Demonstration of scraping product details from an e-commerce website using Parse.
Starting a new project with the URL of the desired e-commerce site.
Three main areas in the Parse client: commands, interactive website view, and data preview.
Scrolling down to find products within a category and navigating through multiple pages.
Selecting all products on all pages by clicking into each one and obtaining more data.
Using the default empty selection command to interact with the first result title.
Previewing data in different formats like CSV, Excel, or JSON.
Highlighting similar elements on the page and selecting multiple items of the same category.
Using relative select commands to relate and extract additional data such as author names and prices.
Renaming selections for better data organization and understanding.
Selecting and extracting data from multiple pages by using the 'next' button and creating a main template.
Creating a new template for product pages with different layouts and adding new select commands for each data point.
Using conditional commands to extract data based on specific label contents.
Testing the project with a test run to ensure correct data extraction and behavior.
Running the project on Parse servers and saving the data in CSV or JSON format.
Availability of an API for integrating scraped data into other applications.
Contacting support for help with personal projects.
Transcripts
Browse More Related Video

ParseHub Tutorial: Scraping 2 eCommerce Websites in 1 Project

Web scraping | Scrape eCommerce Websites Without Coding
ParseHub Tutorial: Directories

Web Scraping to CSV | Multiple Pages Scraping with BeautifulSoup

Industrial-scale Web Scraping with AI & Proxy Networks
ParseHub Tutorial: Pagination (no 'next' button)
5.0 / 5 (0 votes)
Thanks for rating: