Web Scraping Tutorial | Data Scraping from Websites to Excel | Web Scraper Chorme Extension
TLDRIn this informative video, the presenter guides viewers on how to use a free Google Chrome extension for web scraping to efficiently gather data from multiple web pages. The tutorial demonstrates the step-by-step process of extracting car insurance service providers' information from the Yellow Pages business directory, including details such as business names, phone numbers, addresses, websites, and email addresses. The presenter emphasizes the tool's capability to navigate through various pages of listings and compile data effectively, while also discussing the importance of adjusting the scraping intervals to avoid restrictions from the websites. The video concludes with a walkthrough of exporting and cleaning the scraped data, offering a valuable resource for those seeking to collect and organize online information efficiently.
Takeaways
- 🌐 The video is a tutorial on web scraping using a Google Chrome extension.
- 📚 The process involves extracting data from the Yellow Pages business directory for car insurance service providers in New York City and State.
- 🔍 Data collected includes business names, phone numbers, addresses, website URLs, and email addresses.
- 📈 The tool automatically visits multiple pages of search results, compiling information from each business listing.
- 🔧 Installation of the Web Scraper extension is required to begin the scraping process.
- 🛠 Creation of a sitemap is necessary to define the structure and layout for data extraction.
- 🎯 Selectors are used to identify and isolate specific elements on the webpage, such as links, text, and other relevant data.
- 🔄 The tutorial demonstrates how to select multiple links, indicating the tool's capability to handle repetitive tasks efficiently.
- 📊 The script outlines the importance of adjusting settings to avoid restrictions from the website being scraped.
- ⏱️ A delay is recommended between page visits to prevent triggering limitations set by the websites.
- 📋 The final data is collected and can be exported in a CSV format for further analysis or use.
- 🗑️ The video concludes with a brief on cleaning the extracted data to remove any irrelevant or duplicate information.
Q & A
What is the main topic of the video?
-The main topic of the video is about scraping data from websites using a free Google Chrome extension called Web Scraper.
What kind of information is the presenter planning to extract?
-The presenter plans to extract car insurance service providers' information from the Yellow Pages business directory, including their names, phone numbers, addresses, website addresses, and email addresses.
How does the tool automatically visit multiple web pages?
-The tool automatically visits multiple web pages by starting with the first page, then moving on to the second, third, fourth, and so on, gathering business listings information from each page.
What is the total number of results the presenter expects to get from the first three pages?
-The presenter expects to get a total of 90 results from the first three pages, with 30 results per page.
How long does it take to install the Web Scraper extension on Google Chrome?
-It takes a few seconds to install the Web Scraper extension on Google Chrome after clicking the 'Add to Chrome' button and confirming the installation.
What is the first step in creating a new sitemap with the Web Scraper extension?
-The first step in creating a new sitemap is to click on the 'Create New Sitemap' option after clicking on the 'Web Scraper' button that appears when the extension is installed.
How does the presenter select multiple business listing links on the page?
-The presenter selects multiple business listing links by clicking on the 'Add New Selector' button, choosing the first link, and then changing the type from 'Text' to 'Link'. The tool then automatically selects the rest of the listings.
What is the purpose of adding a new selector for each piece of information inside the business listing?
-The purpose of adding a new selector for each piece of information is to specify which data to extract from the business listings, such as the business name, phone number, address, website, and email address.
How does the presenter ensure that the tool visits all the pages with business listings?
-The presenter ensures that the tool visits all the pages with business listings by adding a new selector for the 'pages' and selecting all the 'Next' links that lead to more pages of listings.
What is the recommended interval setting to avoid getting restricted by the website during the scraping process?
-The recommended interval setting to avoid getting restricted is to provide a larger gap, such as 2000 milliseconds or more, between page visits to reduce the chances of being detected and stopped by the website.
How does the presenter export and save the scraped data?
-The presenter exports and saves the scraped data by clicking on the 'Export Data as CSV' button, which downloads the data into an Excel document in CSV format.
What is the final step the presenter takes to clean up the scraped data?
-The final step to clean up the scraped data is to open the CSV file, remove unnecessary fields, and use the 'Find and Replace' function to eliminate any unwanted text, such as 'mailto:', from the email addresses.
Outlines
🌐 Introduction to Web Scraping with Google Chrome Extension
The paragraph introduces the concept of web scraping and outlines the steps to be followed for extracting data from multiple web pages automatically. It highlights the use of a free Google Chrome extension for this purpose and provides an example of extracting car insurance service providers' information from the Yellow Pages directory. The paragraph emphasizes the process of collecting various details such as business names, phone numbers, addresses, websites, and email addresses. It also explains how the tool navigates through different pages of the directory to gather comprehensive listings.
🔍 Setting Up the Web Scraper Extension
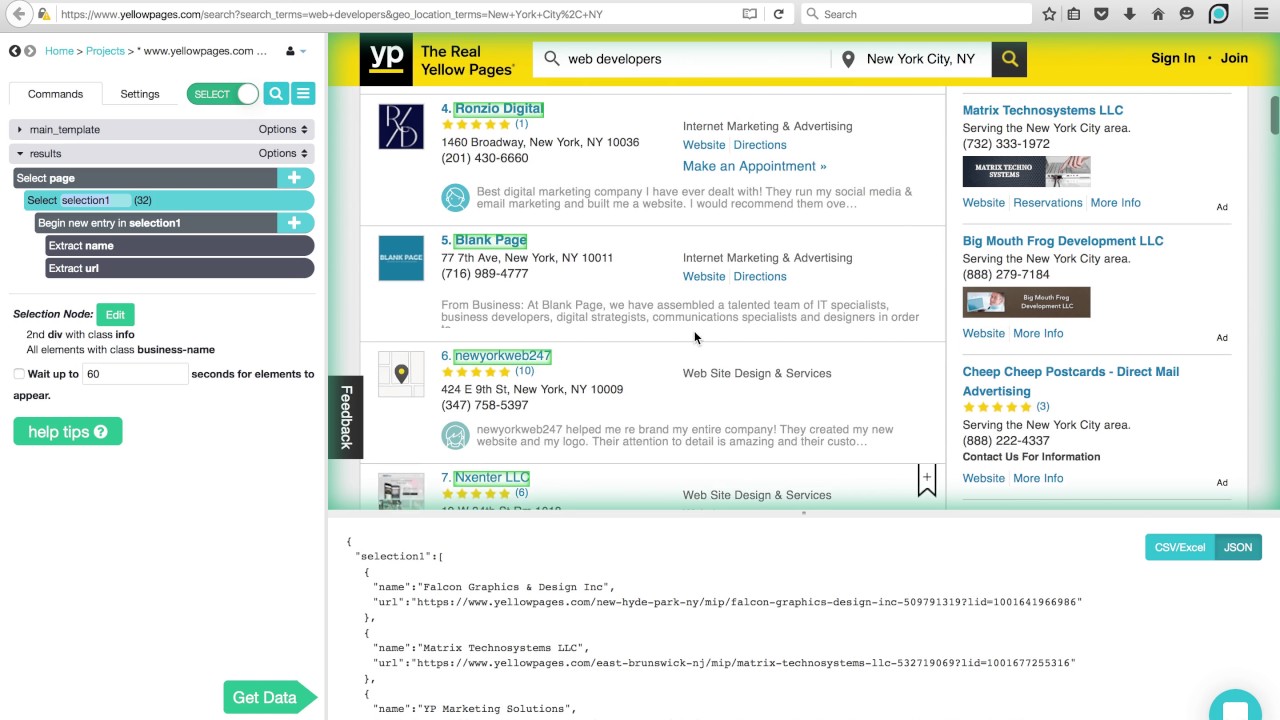
This paragraph details the process of setting up the web scraper extension in Google Chrome. It instructs the viewer on how to install the extension, access the extension page, and add it to Chrome. The paragraph then walks the user through the initial steps of using the extension, such as creating a new sitemap, naming it, and specifying the start URL. It also covers the selection of business listing links as the first step in building the sitemap and saving the selector for future use.
📋 Configuring Selectors for Data Extraction
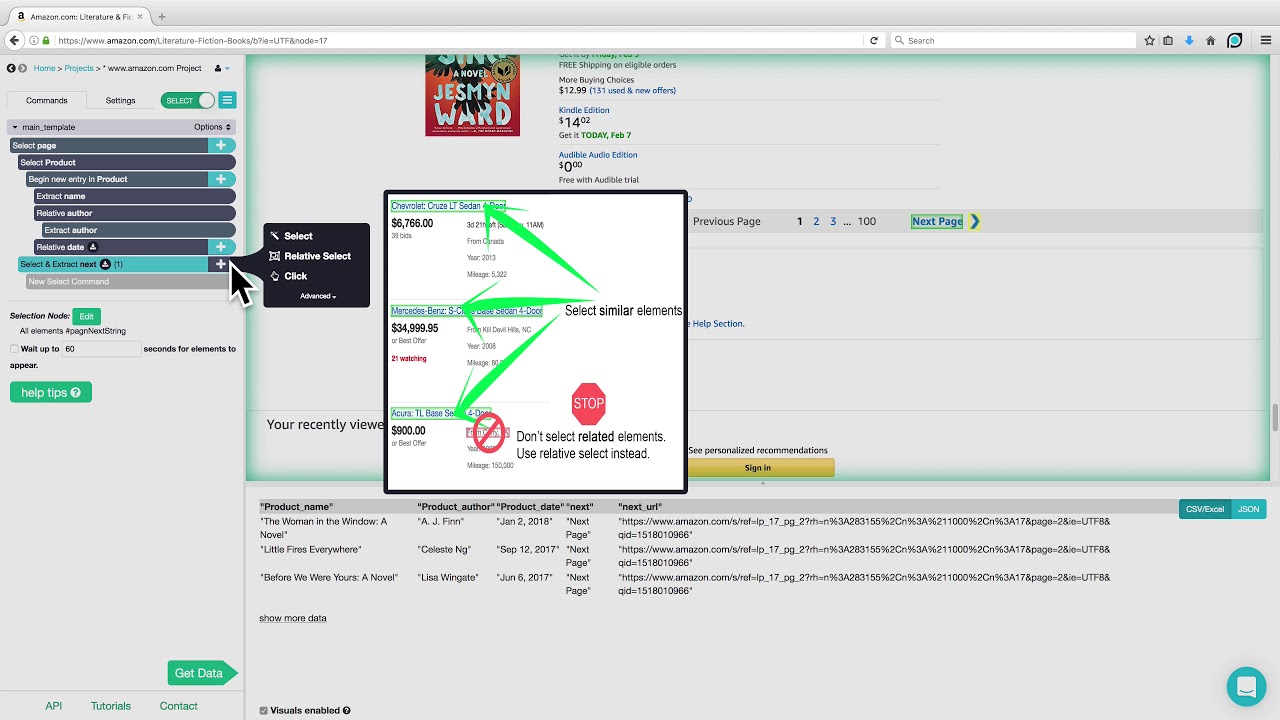
The paragraph focuses on configuring selectors for extracting specific data from the business listings. It explains how to navigate within the business listing and add new selectors for various pieces of information such as the business name, phone number, address, website, and email address. The process involves selecting the relevant elements on the page, saving the selectors, and setting the appropriate type (text or link) for each piece of data. The paragraph also discusses the importance of selecting multiple links and saving the selectors for efficient data extraction.
🔄 Navigating Through Multiple Pages for Data Collection
This paragraph describes the method of instructing the web scraper to navigate through multiple pages of the directory to collect data. It explains how to add a new selector for the 'pages' and set it to link type, allowing the tool to identify and traverse all the pagination links. The paragraph emphasizes the importance of selecting multiple pages and saving the selector to ensure that the scraper can move through the listings effectively. It also touches on the concept of parent selectors and how they are used to refine the scraping process.
🚀 Starting the Scraping Process and Exporting Data
The paragraph outlines the final steps of starting the scraping process by setting an interval for the scraper to avoid restrictions from the website and clicking on the 'start scraping' button. It explains how the tool will visit each page, extract the required information, and display the progress. The paragraph also covers the process of exporting the scraped data into a CSV file, which can be opened and analyzed in an Excel document. Additionally, it provides tips on cleaning the data by removing unnecessary information and duplicates to ensure a refined and accurate dataset.
📈 Finalizing and Presenting the Scraped Data
In this paragraph, the focus is on finalizing the scraped data and presenting it in a clean and organized manner. It discusses the process of removing unnecessary fields and cleaning up the email list by using the 'find and replace' function to eliminate common text strings. The paragraph concludes by summarizing the entire process of data extraction from a business listing website and encourages viewers to like, share, and comment on the video for further assistance. It also prompts viewers to subscribe for more helpful content in the future.
Mindmap
Keywords
💡Web Scraping
💡Google Chrome Extension
💡Sitemap
💡Selectors
💡Data Extraction
💡CSV File
💡Inspect Element
💡Automation
💡Data Cleaning
💡Web Pages Navigation
💡Scraping Intervals
Highlights
Introduction to web scraping and its potential for collecting information from multiple web pages automatically.
Use of a free Google Chrome extension for web scraping, specifically the Web Scraper extension.
Demonstration of extracting data from the Yellow Pages business directory.
Collection of car insurance service providers' information from New York City and state.
Explanation of the tool's ability to visit subsequent pages and gather additional business listings.
Step-by-step guide on installing the Web Scraper extension on Google Chrome.
Creation of a new sitemap within the web scraper extension for the specific directory being scraped.
Selection of business listing links for data extraction using the extension's selector tool.
How to save and name selectors for different pieces of information, such as business names and contact details.
Process of selecting and saving website and email addresses from business profiles.
Explanation of how to navigate and select multiple pages for data scraping.
Importance of setting intervals to avoid restrictions from the website being scraped.
Starting the scraping process and observing the tool visit pages and collect data.
Review of the collected data and its presentation in a CSV file format.
Tips on cleaning the extracted data to remove unnecessary information and duplicates.
Final thoughts on the usefulness of the video and encouragement for viewers to engage with the content.
Transcripts
Browse More Related Video
ParseHub Tutorial: Directories

Web Scraping with ChatGPT is mind blowing 🤯

Web Scrape Text from ANY Website - Web Scraping in R (Part 1)
ParseHub Tutorial: Scraping Product Details from Amazon

Web Scraping with Python and BeautifulSoup is THIS easy!

Web scraping | Scrape eCommerce Websites Without Coding
5.0 / 5 (0 votes)
Thanks for rating: