Wk07-Midterm Review
TLDRThis video script offers a comprehensive midterm review for a course, covering topics such as the properties of normal distribution, the distinction between read depth and count-based data, and the differences between first and second-generation sequencing. It delves into advanced concepts, explains the importance of visualizing data with scatter plots, and discusses the challenges and advances in genome assembly. The script also provides insights into data structures in R, the use of regular expressions, and concludes with practical examples and common pitfalls in data analysis and visualization.
Takeaways
- 📚 The video is a midterm review for a course, likely in a scientific field such as biology or statistics, given the discussion of normal distribution properties and sequencing technologies.
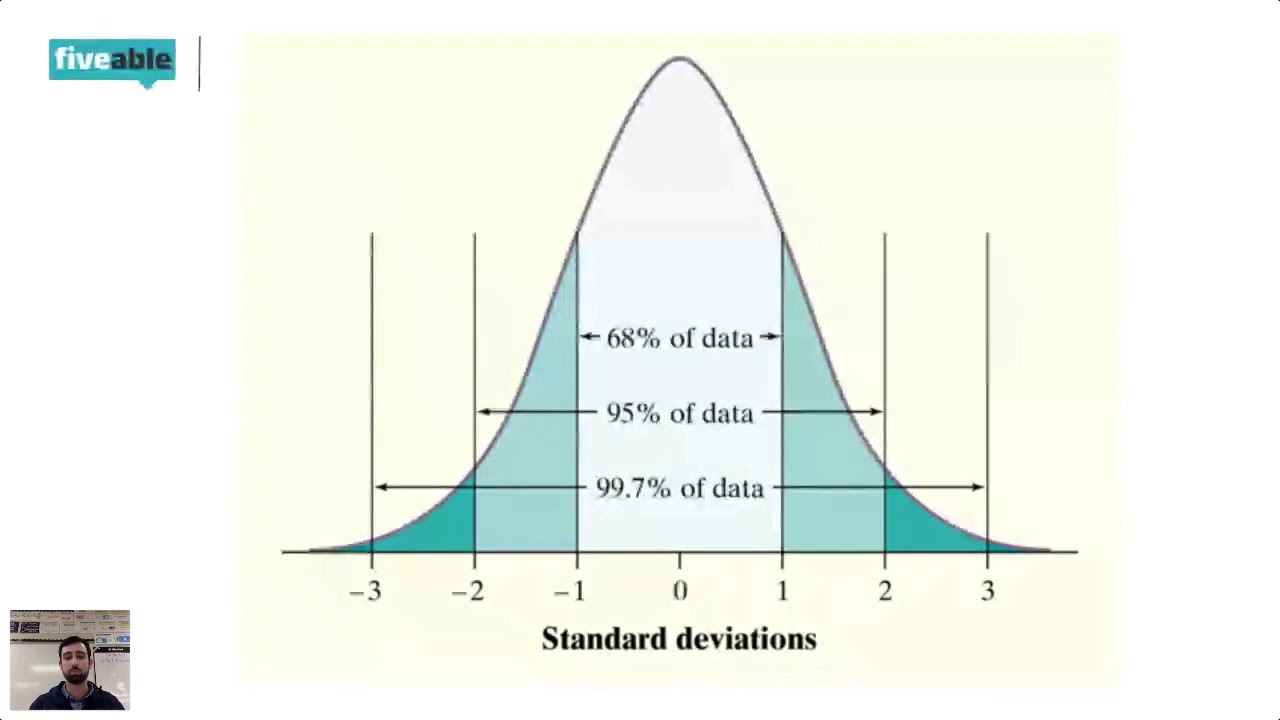
- 📉 A normal distribution is characterized by its symmetry, meaning the likelihood of observations decreases as you move away from the mean, forming a bell-shaped curve.
- ∞ The normal distribution is continuous and extends to infinity, with no discrete values, which is a theoretical concept often violated in practical applications.
- 🔍 The mean and standard deviation are essential parameters of a normal distribution, defining the peak's location and the spread of data points, respectively.
- 🌟 The standard normal distribution is a specific case where the mean is zero and the standard deviation is one, obtained by scaling any normal distribution.
- 📈 The video discusses the difference between read depth and count-based data versus normal distributions, noting that read depths are discrete and positive only, contrasting the continuous nature of normal distributions.
- 🧬 Sequencing technologies have evolved from first to second generation, with Next Generation Sequencing (NGS) allowing massively parallel processing and higher efficiency.
- 🔬 Long-read sequencing has overcome issues with genome assembly, particularly with repetitive sequences, by providing reads longer than the repetitive regions, facilitating more accurate genome assembly.
- 📊 The use of scatter plots and two-dimensional graphics is emphasized for visualizing interactions and correlations between different measurements, unlike one-dimensional graphics like histograms.
- 🔑 The script explains R programming concepts such as data frames, logical vectors, and the importance of understanding order of operations in coding.
- 🧠 The video concludes with a reminder to review all study materials thoroughly, highlighting the importance of deep understanding and checking feedback on difficult topics.
Q & A
What are the main properties of a normal distribution mentioned in the video?
-The main properties of a normal distribution mentioned are that it is symmetrical, continuous, and defined by its mean and standard deviation. The distribution is symmetrical, meaning it can be equally likely to undershoot or overshoot the mean. It is continuous, extending to infinity, and does not have discrete values, which is often violated in practical science.
What is the difference between a normal distribution and a standard normal distribution?
-A normal distribution can have any mean and standard deviation, while a standard normal distribution is a specific normal distribution with a mean of zero and a standard deviation of one. It is obtained by subtracting the mean and dividing by the standard deviation of any normal distribution.
How does count-based data differ from normal distributions?
-Count-based data, such as read depths, is discrete and positive-only, violating the symmetry and continuity of normal distributions. It often follows a negative binomial model rather than a normal distribution.
What is the major difference between first and second generation sequencing?
-The first generation sequencing could only read a single sequence at a time, requiring separate solutions for each sequence. Second-generation sequencing (Next Generation Sequencing, NGS) is massively parallel, allowing for the sequencing of millions of clusters at a time at a nano scale.
How did long-read sequencing overcome issues with genome assembly?
-Long-read sequencing overcame issues with repetitive sequences in the genome by providing reads that are longer than the repetitive regions, allowing for the identification of unique information that can pinpoint the exact location of a sequence within the genome.
Why is it beneficial to visualize biological measurements using scatter plots or other two-dimensional graphics?
-Two-dimensional graphics like scatter plots can show interactions between different measurements, revealing correlations that one-dimensional graphics like histograms cannot. This helps in understanding the relationships and potential causations within biological systems.
What is the significance of the order of operations in coding and how can it be managed?
-The order of operations is crucial in coding as it determines the sequence of execution. It can be managed by using parentheses to explicitly specify the order, especially when the default left-to-right sequence is not sufficient.
What is the difference between extracting a single column and multiple columns from a data frame in R?
-Extracting a single column from a data frame simplifies the result to a vector of that column's data type by default, while extracting multiple columns retains the data frame structure.
How can you determine the class of an object in R after performing various extractions and manipulations?
-The class of an object in R after extractions and manipulations depends on the nature of the data and the type of operation performed. For example, extracting a single column from a data frame results in a vector of that column's data type, while extracting multiple columns or rows retains the data frame class.
What is the purpose of the 'collapse' function in R when working with vectors?
-The 'collapse' function in R is used to concatenate elements of a vector into a single string, with the specified separator between elements. This can be useful for creating new column names or analyzing multiple things simultaneously.
How can you use logical vectors to filter rows in a data frame based on multiple conditions?
-Logical vectors can be used to create conditions for filtering rows in a data frame. By using the '&' (and) or '|' (or) operators, you can combine multiple conditions and extract rows where all or any of the conditions are true.
What is the importance of understanding the behavior of functions and their arguments in R when solving problems?
-Understanding the behavior of functions and their arguments in R is crucial for correctly solving problems. It ensures that the functions are applied with the correct order and context, leading to accurate results.
Why is it necessary to check the class of an object before performing operations in R?
-Checking the class of an object before performing operations in R is necessary because different classes have different behaviors and allowed operations. This ensures that operations are valid and do not result in errors.
Outlines
📚 Midterm Review for Spring 2024
This paragraph introduces a midterm review video for the spring of 2024. The speaker outlines the topics to be covered, starting with the properties of a normal distribution. Key points include the symmetry of the distribution, its continuous nature, and the importance of the mean and standard deviation in defining it. The speaker also clarifies misconceptions about the mean and standard deviation of a normal distribution, emphasizing that not all normal distributions have a mean of zero and a standard deviation of one, which is a characteristic of the standard normal distribution. The paragraph concludes with a transition to the next topic, which involves comparing read depth and count-based data with normal distributions.
🔍 Differences Between Normal Distributions and Count-Based Data
The speaker discusses the differences between normal distributions and count-based data, such as read depths in sequencing. They explain that read depths are discrete values and positive only, which violates the symmetry of a normal distribution. The speaker also mentions that count-based data is never truly a normal distribution, as it is discrete and often modeled by the negative binomial model, which accounts for the process of sampling finite locations multiple times. The paragraph highlights the complexity of accurately modeling biological data and the move away from normal distributions in advanced models.
🧬 Sequencing Technologies and Genome Assembly
This section delves into the evolution of sequencing technologies, contrasting first and second-generation sequencing. The speaker explains that first-generation sequencing was limited to reading single sequences at a time, requiring separate physical solutions for each sequence. In contrast, Next Generation Sequencing (NGS) allows for massively parallel processing at a nano scale, significantly increasing efficiency. The speaker also discusses the challenges of genome assembly, particularly with repetitive sequences, and how long-read sequencing has overcome these issues by providing reads longer than the repetitive regions, enabling more accurate genome assembly.
📊 Visualization of Biological Measurements
The speaker emphasizes the importance of visualizing biological measurements using two-dimensional graphics like scatter plots, as opposed to one-dimensional graphics like histograms. The reason is that two-dimensional graphics can reveal interactions and correlations between different measurements, providing insights into the biological system. The speaker also touches on the use of data frames in R and how they are identified, including their structure and properties.
🔢 Data Frame Operations and Class Identification
The paragraph discusses operations performed on data frames in R, such as extraction of specific rows and columns. The speaker explains that extractions do not simplify if there are multiple containers, preserving the integrity of the data. They also provide examples of how data frames can be manipulated and the importance of understanding the class of each object in the outputs, such as character vectors, data frames, and numeric vectors.
🤔 Order of Operations and Logical Vectors
This section focuses on the order of operations in R, using an example of calculating the average miles per gallon for straight engine cars from the 'mtcars' dataset. The speaker advises thinking through the order of operations in terms of what needs to happen for the next step to occur and suggests using parentheses for clarity. They also explore the concept of logical vectors and how they can be coerced into numeric values for calculations, providing various methods to determine the number of false values in a logical vector.
📈 Conditional Data Extraction and Plotting
The speaker presents a task of extracting rows from the 'empty cars' dataset where certain conditions are met, such as the 'vs' column being equal to one and the 'horsepower' being less than 100. They demonstrate the use of logical vectors and the '&' operator to combine conditions. The paragraph also includes an example of plotting data from the 'iris' dataset, focusing on rows where 'petal length' or 'petal width' exceed certain values, and the importance of understanding conditional extractions for data analysis.
❓ Error Handling and Function Assignments
This section discusses error handling in R when dealing with logical checks and function assignments. The speaker explains that R produces an error if a logical check receives more than one value, as it requires a single true or false outcome. They also explore the concept of function assignment to objects and the importance of understanding when and how functions are executed within an R session.
🚀 Physics Calculations with R
The speaker presents a physics problem involving the motion of an object under constant acceleration, which can be solved using R. They demonstrate how to define a function for calculating displacement based on time, initial velocity, and acceleration. The example involves finding the time when an object thrown into the air returns to the starting point, showcasing the application of R for scientific calculations.
🔍 Regex Patterns and String Manipulation
This paragraph covers the use of regular expressions (regex) in R for pattern matching and string manipulation. The speaker provides examples of constructing regex patterns to match specific criteria, such as containing an 'e' followed by an 'm', or starting with an 's' and ending with an 'n'. They also explain the use of 'gsub' for replacing parts of a string based on a pattern and the importance of understanding regex symbols for effective text processing.
📊 Advanced Data Visualization Techniques
The speaker discusses advanced techniques for data visualization in R, particularly focusing on the use of 'ggplot2' for creating complex plots. They address common issues such as layering plots and adjusting the order of plot elements, such as ensuring that points appear on top of violin plots. The paragraph also touches on the use of aesthetics to map variables to visual properties, enhancing the clarity and information conveyed by the plots.
Mindmap
Keywords
💡Normal Distribution
💡Standard Deviation
💡Continuous Data
💡Discrete Data
💡Sequencing
💡Genome Assembly
💡Scatter Plot
💡DataFrame
💡Logical Vector
💡Order of Operations
💡Negative Binomial Model
Highlights
Introduction to the midterm review for the spring of 2024.
Discussion on the properties of a normal distribution, emphasizing its symmetry and continuous nature.
Clarification of misconceptions regarding the mean and standard deviation of a normal distribution.
Explanation of the standard normal distribution and its relation to any normal distribution.
Distinguishing between read depth and count-based data in comparison to normal distributions.
Insight into the negative binomial model as a better fit for count-based data like read depth.
Overview of the major differences between first and second-generation sequencing technologies.
The advantage of Next Generation Sequencing (NGS) in terms of parallelism and efficiency.
Long-read sequencing's ability to overcome issues with repetitive sequences in genome assembly.
The importance of visualizing biological measurements on scatter plots for understanding interactions.
Explanation of data frames in R, their structure, and how they differ from matrices.
The behavior of R in not simplifying data types during extractions to prevent information loss.
Analysis of the class of objects in R and how extractions affect their class.
Understanding the order of operations in R and how to interpret complex expressions.
The use of logical vectors in R for data extraction based on conditions.
Application of regex (regular expressions) in R for pattern matching and data manipulation.
Common mistakes and misunderstandings when working with data frames and object classes in R.
Final review advice on thoroughly understanding the course material and preparing for the exam.
Transcripts
Browse More Related Video

Introduction to Descriptive Statistics

Master Pivot Tables in 10 Minutes (Using Real Examples)
AP Stats - Cram Review (2019)

Descriptive statistics and data visualisation. An introduction to statistics and working with data
Discrete v/s Continuous Data - What ? How ? || Discrete Data || Continuous Data || Basic Statistics

Quantitative Data Analysis 101 Tutorial: Descriptive vs Inferential Statistics (With Examples)
5.0 / 5 (0 votes)
Thanks for rating: