AP Stats - Cram Review (2019)
TLDRIn this comprehensive AP Statistics review session, Shane Durkin addresses the first semester's key topics, including exploring one and two variable data, collecting data, and delving into probability concepts. He emphasizes the importance of understanding statistical concepts like mean, median, mode, and standard deviation, as well as the significance of graphs in data analysis. Durkin also covers the normal distribution, z-scores, and linear regression, providing insights into predicting outcomes and interpreting data. The session is interactive, with multiple-choice questions and an invitation for students to ask questions, ensuring a thorough understanding of the material.
Takeaways
- 📚 Shane Durkin introduces the first semester review for AP Statistics, emphasizing the importance of understanding the course material for the upcoming AP exam.
- 🔍 The review session is structured to cover four main units: exploring one-variable data, exploring two-variable data, collecting data, and probability random variables and distributions.
- 📈 In exploring data, students learn to differentiate between categorical and quantitative data, and how to represent them using various graphs like bar graphs, histograms, and box plots.
- 📊 Descriptive statistics are crucial for summarizing data, with measures of center (mean, median) and spread (range, interquartile range, variance, standard deviation) being key elements.
- 📉 The normal distribution and its properties, including the empirical rule (68-95-99.7 rule), are fundamental in understanding data distribution and making inferences.
- 🔢 Z-scores are used to standardize data from different distributions, allowing for comparison and the identification of outliers.
- 📝 The importance of context is highlighted when describing data, ensuring that the discussion is relevant to the data set being analyzed.
- 🤝 Linear relationships in bivariate data are explored through scatter plots, and the concept of explanatory and response variables is introduced.
- ↗️ The direction, form, strength, and unusual patterns in bivariate data are essential aspects to consider when describing relationships between two variables.
- 🧭 The least squares regression line is a vital tool for predicting values based on a linear relationship between two variables.
- 🔧 R-squared and residual analysis are important for evaluating the fit of the regression line to the data and understanding the prediction error.
Q & A
What is the purpose of the video session conducted by Shane Durkin?
-The purpose of the video session is to provide a first-semester review for AP Statistics, covering key concepts and addressing questions from students.
What platform is mentioned for following updates and staying on top of grades?
-The platform mentioned for updates is 'Think Fiveable,' which is available on various social media platforms like Twitter, Instagram, and YouTube.
How does Shane Durkin plan to structure the review session?
-Shane plans to structure the session by going through a document highlighting important AP Statistics topics and skipping the PowerPoint for a more streamlined approach with bullet points.
What are the four main units that the first semester of AP Statistics typically covers according to the script?
-The four main units are exploring one-variable data, exploring two-variable data, collecting data, and probability random variables and probability distributions.
Why is probability considered a difficult unit for most students?
-Probability is considered difficult because it involves complex concepts that can be challenging to grasp and requires thorough review for the AP exam.
What is the importance of statistics as explained in the script?
-Statistics is important because it allows us to make inferences about a population by analyzing a representative sample, keeping probability in mind.
What are the different ways to graph categorical data as mentioned in the script?
-Categorical data can be graphed using bar graphs, pie charts, and other methods, with the key difference being that bars in bar graphs do not touch.
What is the difference between a population mean (mu) and a sample mean (x bar) according to the script?
-The population mean (mu) refers to the average of an entire population, while the sample mean (x bar) refers to the average of a sample taken from that population.
What is the empirical rule, and how is it used in the context of normal distributions?
-The empirical rule, also known as the 68-95-99.7 rule, states that for a normal distribution, approximately 68% of data points fall within one standard deviation of the mean, 95% within two standard deviations, and 99.7% within three standard deviations.
What is a z-score, and how is it used in statistics?
-A z-score represents the number of standard deviations a data point is from the mean. It is used to standardize data and compare data points across different distributions.
What are the key components of a scatter plot when exploring bivariate data?
-The key components of a scatter plot are the explanatory variable (independent variable) and the response variable (dependent variable), which are used to identify trends and relationships between two quantitative variables.
What does R-squared represent in the context of linear regression?
-R-squared, or the coefficient of determination, represents the proportion of the variance in the dependent variable that is predictable from the independent variable(s).
What is the difference between a census and a sample survey in data collection?
-A census involves collecting data from every individual in the population, while a sample survey involves collecting data from a subset of individuals to make inferences about the entire population.
What are the four key aspects of a well-designed experiment according to the script?
-The four key aspects of a well-designed experiment are comparison, random assignment, replication, and blinding (if applicable).
What is the purpose of a residual in the context of linear regression?
-A residual is the difference between the actual data point and the predicted data point by the regression line. It helps in understanding the error in prediction and can be used to assess the fit of the model.
What does the script suggest for determining the median grade from a frequency table?
-The script suggests that to determine the median grade from a frequency table, one should identify the interval that contains the 50th percentile of the data, which is the middle value when the data is ordered from least to greatest.
How can you quickly determine if the mean age of a group has decreased after one person leaves the group?
-You can quickly determine if the mean age has decreased by calculating the new total age sum after the person's age is removed and then dividing by the new number of people in the group.
What is the significance of drawing a normal distribution curve when solving problems related to it?
-Drawing a normal distribution curve is significant because it helps visualize the problem, ensures that the teacher sees the understanding of the concept, and aids in accurately determining the area under the curve for a given z-score.
Outlines
📚 AP Statistics First Semester Review Introduction
Shane Durkin initiates the first semester review session for AP Statistics, addressing technical difficulties and inviting questions. He outlines the session's plan, which includes a walkthrough of the first semester material, focusing on four main units: exploring one-variable and two-variable data, data collection, and probability. He emphasizes the importance of statistics in making inferences about populations from samples and encourages students to follow Fiveable for updates and exam preparation.
📊 Exploring Data with Visual Representations and Statistics
The paragraph delves into the methods of exploring data, differentiating between categorical and quantitative data, and the various graphs used for each. It explains the importance of summary statistics like mean, median, mode, range, quartiles, variance, and standard deviation in understanding data distribution. The use of technology, specifically the TI-84 or 83 calculator, is highlighted for ease of calculation. The speaker also discusses the significance of context when describing data and the concept of the normal distribution, empirical rule, and z-scores.
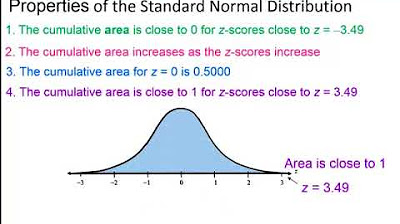
📈 Understanding Normal Distribution and Z-Scores
This section focuses on the characteristics of normal distributions, including their symmetry, peak, and definition by mean (mu) and standard deviation. The empirical rule (68-95-99.7 rule) is introduced to describe the distribution of data points around the mean. Z-scores are explained as a method to standardize and compare data across different distributions, with examples provided to illustrate their application. The paragraph also mentions the use of calculator functions for normal distribution calculations.
🤝 Analyzing Bivariate Data with Scatter Plots and Linear Relationships
The exploration of bivariate data is discussed, emphasizing the distinction between explanatory and response variables. Scatter plots are introduced as a tool for visualizing bivariate data, and the importance of identifying the direction, form, strength, and unusual patterns in data relationships is highlighted. The concept of the least squares regression line as a predictor is introduced, along with its components: slope, y-intercept, and the process of making predictions based on the line of best fit.
🔍 Delving into Linear Regression and Data Prediction
The paragraph discusses the intricacies of linear regression, including the calculation of the line of best fit and its use in predicting outcomes based on explanatory variables. It explains the meaning of residuals, the importance of context in data interpretation, and the potential issues with extrapolation beyond the range of the original data set. The concept of R-squared as a measure of the variation explained by the regression line is introduced, along with a template for interpreting R-squared values.
🔬 Collecting Data Through Surveys and Experiments
This section covers the various methods of data collection, including census, sample surveys, and the importance of avoiding bias. It differentiates between different sampling techniques such as simple random sampling, cluster sampling, and stratified random sampling. The paragraph also explains the difference between observational studies and experiments, highlighting the role of treatments and confounding variables in experiments.
📝 Understanding the Nature of Surveys and Experimental Design
The focus shifts to the specifics of surveys and experimental design, emphasizing the importance of representative sampling and the avoidance of bias. The paragraph discusses the types of bias that can occur in surveys and the key elements of a well-designed experiment, including comparison, random assignment, replication, and the optional use of blinding.
📉 Interpreting Data with Frequency Tables and Medians
The paragraph examines the use of frequency tables to determine median grades and discusses the implications of a median being significantly larger than the mean, suggesting a left skew in the data distribution. It also touches on the process of calculating the new mean when a member of a group leaves, altering the average age of the remaining group.
📊 Standard Normal Distribution and Z-Score Calculations
This section explains how to use the standard normal distribution table and calculator functions to find areas corresponding to z-scores. It provides examples of calculating the probability of a z-score being greater than a certain value and the area between two z-scores. The importance of drawing the normal distribution curve to visualize the problem and ensure full credit on exams is emphasized.
✍️ Applying Linear Regression in Predictive Analysis
The paragraph discusses the application of linear regression in predicting outcomes, such as exam scores based on study time or timber volume based on tree diameter. It explains the process of using the least squares regression line for predictions and the significance of using the correct variables in the prediction equation.
📉 Misconceptions about Regression Lines and Residuals
The final paragraph addresses common misconceptions about regression lines and residuals. It clarifies that a positive residual does not necessarily mean the point is near the right edge of the scatter plot, and a positive slope is not a requirement for a least squares regression line. The paragraph concludes with a discussion about the relationship between residuals and the position of data points relative to the regression line.
🗓️ Wrapping Up the Session and Encouraging Feedback
Shane Durkin concludes the review session by addressing potential questions and offering to schedule another session if needed. He provides his email for students to reach out with questions and encourages feedback to improve future sessions. The paragraph ends with a reminder to students about the importance of understanding the material covered during the review.
Mindmap
Keywords
💡AP Statistics
💡Exploring Data
💡Categorical Data
💡Quantitative Data
💡Summary Statistics
💡Normal Distribution
💡Z-Score
💡Linear Regression
💡Residual
💡R-Squared
💡Probability
💡Experiment
💡Sampling
Highlights
Introduction to the AP Statistics semester one review session by Shane Durkin, addressing technical difficulties and inviting questions.
Emphasis on following Fiveable on various platforms for updates and assistance in passing the AP exam.
Overview of the first semester covering four main units: exploring one-variable data, two-variable data, data collection, and probability.
Explanation of the importance of statistics in making inferences about populations from sample data.
Discussion on the difference between categorical and quantitative data and their respective graphing methods.
Introduction to summary statistics, including mean, median, mode, range, quartiles, variance, and standard deviation.
Use of the TI-84/83 calculator for statistical calculations and its significance in the AP exam.
Description of the normal distribution, empirical rule, and the concept of z-scores for standardized comparison.
Importance of drawing normal distribution curves to visualize and solve problems effectively.
Analysis of bivariate data through scatter plots and the identification of explanatory and response variables.
Explanation of linear regression, least squares, and the prediction of outcomes based on a linear model.
Differentiation between positive and negative residuals and their implications on the accuracy of predictions.
Introduction to r-squared as a measure of the proportion of variance in the dependent variable that is predictable from the independent variable.
Discussion on various methods of data collection, including census, sample surveys, and the importance of avoiding bias.
Explanation of different sampling techniques like simple random sample, cluster, and stratified random sample.
Overview of experiments versus observational studies, focusing on the imposition of treatments and potential confounding variables.
Practice of multiple-choice questions related to statistics concepts, aiming to solidify understanding and prepare for exams.
Final review and opportunity for students to ask remaining questions, emphasizing the importance of feedback for improvement.
Transcripts
Browse More Related Video

AP Psychology Statistics Simplified: Normal Distribution, Standard Deviation, Percentiles, Z-Scores

Introduction to Descriptive Statistics
Elementary Statistics - Chapter 6 Normal Probability Distributions Part 1

Elementary Stats Lesson #3 A

Live Day 2- Basic To Intermediate Statistics

AP Statistics 10-Minute Recap
5.0 / 5 (0 votes)
Thanks for rating: