Introduction to Bivariate Data (1 of 2: Dependent & independent variables)
TLDRThe transcript discusses the concept of bivariate data, contrasting it with single variable data, and uses the personal example of running to illustrate the relationship between two variables: distance and pace. It emphasizes understanding which variable is independent and which is dependent, where the latter changes in response to the former. The discussion highlights the importance of recognizing these relationships in data analysis.
Takeaways
- 📊 Data analysis involves examining numbers for hidden patterns, such as bimodality where data has two distinct peaks or common scores.
- 🔢 The concept of modality is crucial in data analysis; it refers to the most frequently occurring score in a data set, which can be bimodal in this case.
- 📈 Mean and standard deviation can be less meaningful in bimodal data sets because the mean does not represent any group accurately.
- 📋 Single variable data focuses on one quantity of interest, like height in the example of students' heights.
- 🔄 Bivariate data, on the other hand, involves two changing quantities, allowing for more complex comparisons and analyses.
- 🏃 The example of personal bivariate data shared involves running distance and pace, demonstrating how two variables can be related.
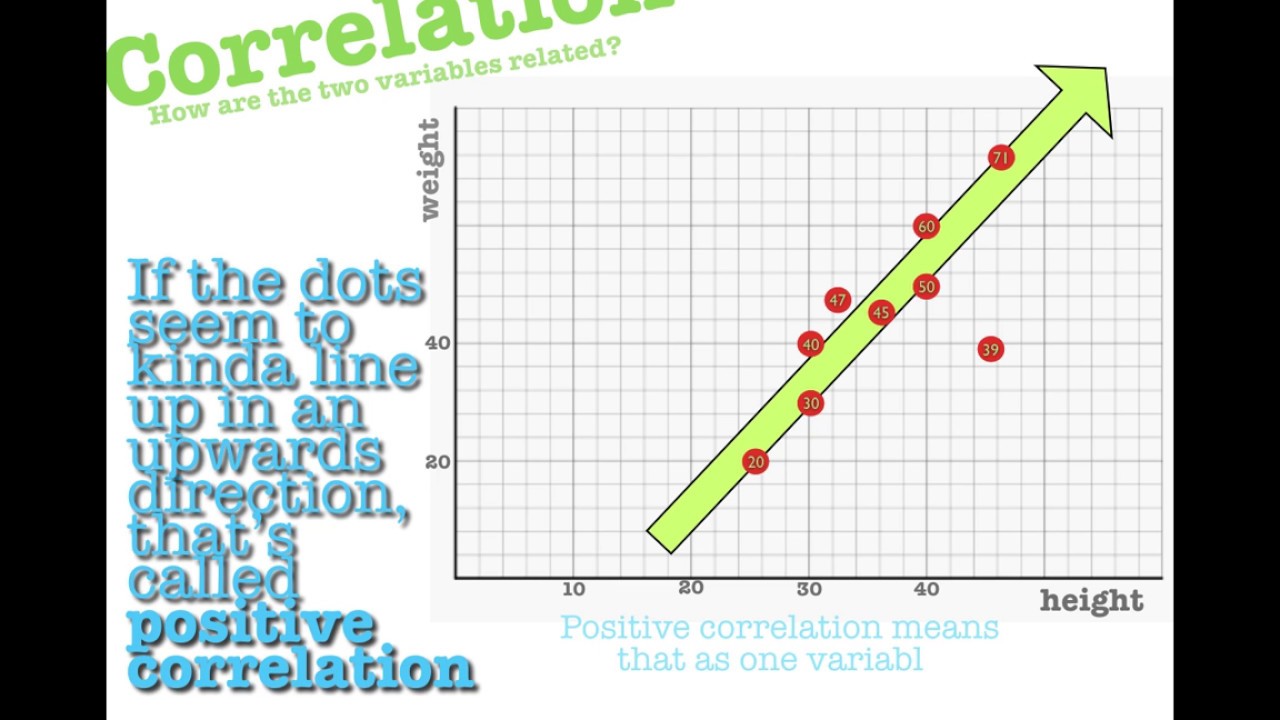
- 📊 In bivariate data, one axis typically represents the independent variable (e.g., distance), and the other represents the dependent variable (e.g., pace).
- 🕒 The pace in the running example is a continuous numerical variable, indicating the time taken to run a kilometer.
- 🤔 Determining the independent and dependent variables in a data set can be tricky and may require discussion and reasoning.
- 📈 Understanding the relationship between variables is essential for proper data interpretation and can reveal insights such as personal fitness progress.
- 📝 When presenting data, it's important to note the absence of labels and units on the axes, which can provide clues about the nature of the data (e.g., whole numbers for counts in single variable data).
Q & A
What is the main topic of discussion in the transcript?
-The main topic of discussion is the analysis of bimodal data and the transition from single-variable data to bivariate data in the context of advanced statistics.
What is the significance of the feature that starts with 'm' or 'b' in the data set mentioned?
-The significant feature is modality, specifically bimodality, which indicates that there are two distinct peaks or common scores within the data set.
Why does the mean become less meaningful in bimodal data sets?
-The mean becomes less meaningful in bimodal data sets because it does not represent any specific group of data points effectively, as the data is divided into two distinct groups around the two modes.
What is the difference between single-variable and bivariate data?
-Single-variable data focuses on one changing quantity, while bivariate data involves two changing quantities, allowing for the comparison and analysis of two different types of data points.
How does the speaker's personal bivariate data relate to their running habits?
-The speaker's personal bivariate data represents the distances they have run (horizontal axis) and their pace (vertical axis), showing their performance in terms of speed for different running distances.
What is the significance of the number 21.1 on the vertical axis of the speaker's bivariate data plot?
-The number 21.1 signifies a half marathon distance, which is the speaker's goal to achieve in terms of running distance.
What are the two types of variables in bivariate data, and how do they relate to each other?
-In bivariate data, there are two types of variables: independent and dependent. The independent variable can be freely changed, while the dependent variable changes in response to the independent variable.
How does the concept of modality apply to the data set discussed in the transcript?
-Modality refers to the most common score or value in a data set. In the discussed data set, bimodality is present, indicating two common values or 'peaks' in the data distribution.
What is the role of the standard deviation in bimodal data sets?
-The standard deviation's role in bimodal data sets is less meaningful because it measures the spread of data around the mean, which does not accurately represent the data distribution in cases where there are two distinct groups of data points.
Why does the speaker emphasize the importance of understanding the terminology used in statistics?
-The speaker emphasizes the importance of understanding terminology to ensure that individuals can accurately interpret and analyze data, recognizing the simple ideas underlying complex statistical terms.
How does the speaker's experience with running illustrate the application of bivariate data analysis?
-The speaker's running experience illustrates the application of bivariate data analysis by showing how two variables, distance and pace, can be analyzed together to understand performance and progress over time.
Outlines
📊 Data Analysis of Student Heights
The paragraph begins with a reflection on a previous data set presented to the audience, focusing on the heights of students. It introduces the concept of a bimodal distribution, where the data set has two distinct modes. The speaker emphasizes the importance of recognizing such features when interpreting data, as it affects the meaningfulness of statistical measures like the mean and standard deviation. The paragraph also highlights the nature of single-variable data and transitions into a discussion about moving beyond this to more complex data types in advanced statistics, setting the stage for the introduction of bivariate data.
🏃♂️ Personal Bivariate Data on Running
This paragraph delves into the concept of bivariate data using the speaker's personal running data as an example. It explains that bivariate data involves two variables that change, and it introduces the idea of numerical and continuous data. The speaker clarifies the meaning behind the data points, revealing that they represent distances run and the corresponding pace. The paragraph further discusses the notion of independent and dependent variables, suggesting that there is a relationship between the two and one variable changes in response to the other. The speaker encourages the audience to consider which variable might be independent and which dependent in the context of the running data presented.
Mindmap
Keywords
💡data
💡modality
💡mean
💡standard deviation
💡single variable data
💡bivariate data
💡independent variable
💡dependent variable
💡bimodal distribution
💡pace
💡distance
Highlights
The discussion revolves around analyzing a set of data related to students' heights, which was presented the previous week.
A key feature of the data set is its bimodality, meaning it has two distinct peaks or common heights among the students.
The concept of modality was reviewed, emphasizing that in bimodal data, the mean and standard deviation may not be as meaningful.
The importance of understanding data characteristics was stressed, particularly the difference between single variable and bivariate data.
Single variable data involves only one quantity of interest, such as height, and the calculations involve pressing the 'one var single variable' button on a calculator.
Bivariate data, in contrast, involves two changing quantities, offering a richer set of information for analysis.
The lecture introduced the concept of bivariate data with a focus on understanding the simple idea behind the terminology.
An example of bivariate data was shared, which was personal to the speaker and related to running distances and pace.
The speaker's running data showed distances on the horizontal axis and pace (time per kilometer) on the vertical axis.
The data was continuous and numerical, with no specific units or labels on the axes, highlighting the abstract nature of bivariate data.
The speaker's personal goal of completing a half marathon (21.1 kilometers) was mentioned, providing context to the data.
The concept of independent and dependent variables was introduced, with the understanding that one variable changes in response to the other.
The challenge of identifying which variable is independent and which is dependent in the running data was presented to the audience.
The significance of understanding the relationship between variables in bivariate data was emphasized for accurate analysis and interpretation.
The speaker invited the audience to vote on their opinion about the independent and dependent variables, promoting active engagement.
Transcripts



5.0 / 5 (0 votes)
Thanks for rating: