Elementary Stats Lesson #6
TLDRThis lesson delves into bivariate data analysis, focusing on the least squares regression line for predicting values based on a linear relationship. The instructor emphasizes understanding the formulas for slope and y-intercept rather than memorization, highlighting the importance of the correlation coefficient 'r' in determining linear association. The script guides through hand calculations and calculator methods for model generation, discusses the limitations of 'r', and introduces the concept of 'r-squared' as a measure of model effectiveness. The caution against extrapolation and the distinction between correlation and causation conclude the lesson, urging students to approach data analysis with critical thinking.
Takeaways
- 📚 The lesson continues the discussion on bivariate data, focusing on the least squares regression line for predicting 'y' values from given 'x' values.
- 🔍 Two methods for calculating the least squares regression line are introduced: by hand and using a calculator, emphasizing the importance of understanding the formulas rather than memorizing them.
- 📈 The correlation coefficient 'r' is pivotal, with values ranging from -1 to 1, indicating the strength and direction of a linear relationship between 'x' and 'y'.
- 🚫 A reminder that the correlation coefficient should not be overused and is only applicable for linear associations, not other types of relationships.
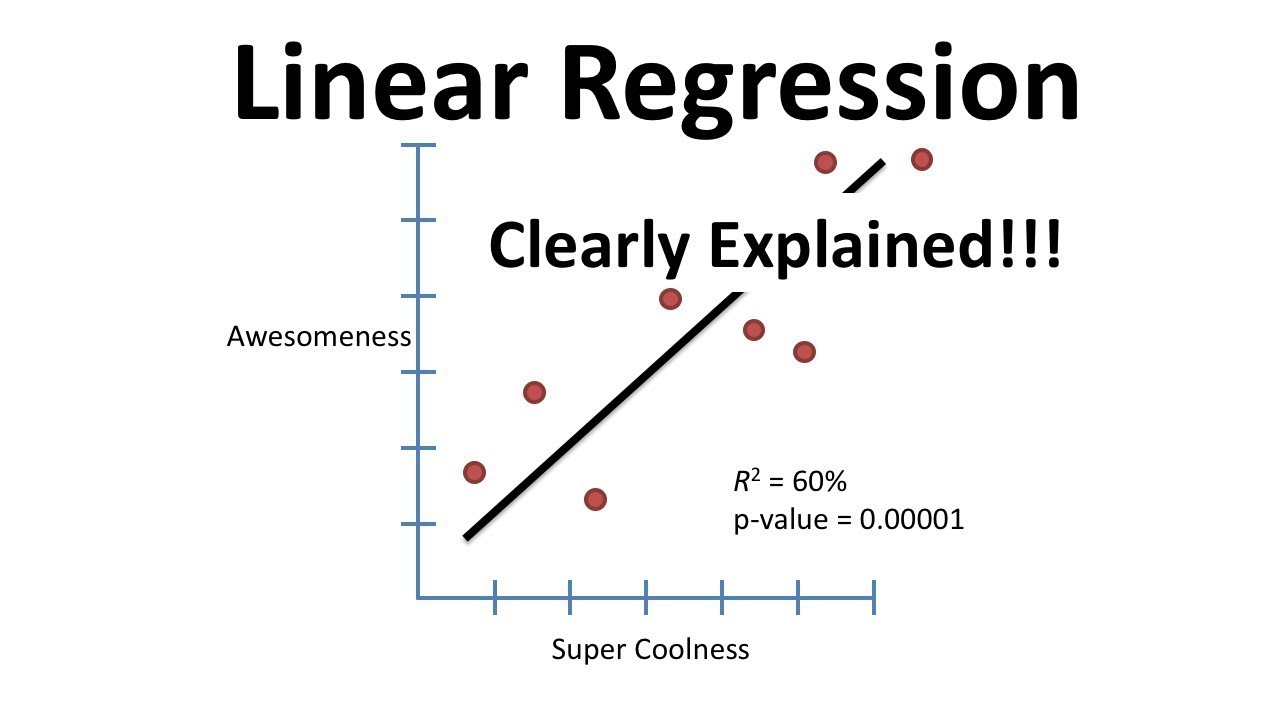
- 📊 The importance of constructing a scatter plot to visually assess the linear association before calculating 'r' is highlighted, along with using a critical value table to validate the linear relationship.
- 🧮 An example is provided to illustrate the manual calculation of the least squares regression line using given summaries like averages and standard deviations.
- 🤔 The script discusses the limitations of using the least squares regression line for predicting 'y' when the correlation coefficient is low, as in the example with parental income and child IQ.
- 🛠️ The calculator method for determining the least squares regression line is preferred for its ease and accuracy, demonstrated with a sample bivariate data set.
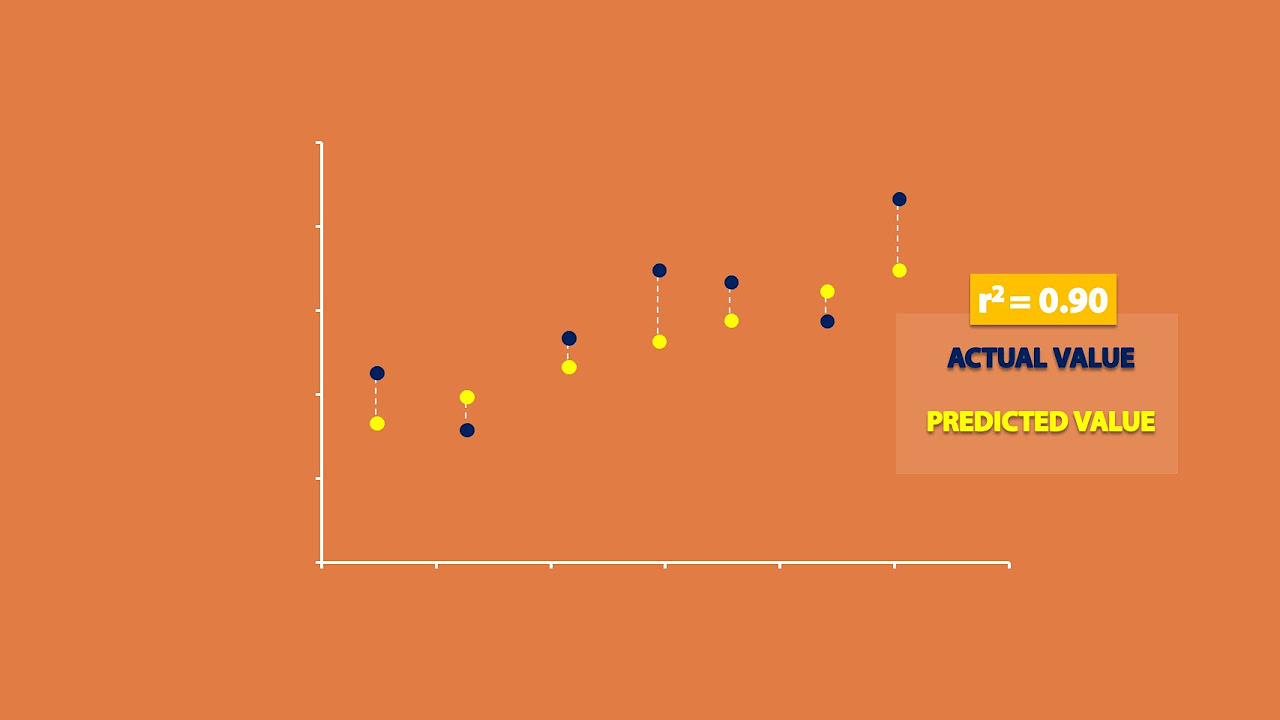
- 📉 The script introduces the concept of 'r-squared' as a measure of how well the regression line describes the relationship between 'x' and 'y', with a higher value indicating a better fit.
- ⚠️ A cautionary note is given against extrapolation, which is using the regression line to predict values outside the range of the collected data, as it can lead to unreliable predictions.
- 🔑 The coefficient of determination (r-squared) is key for understanding the quality of the model, indicating the proportion of the total variation from the average in 'y' that is explained by the model.
Q & A
What is the primary focus of the second half of chapter four in the textbook?
-The primary focus is on continuing the bivariate data discussion started in the previous lesson, specifically on the least square regression line and its application.
What are the two methods discussed for generating the least square regression line?
-The two methods discussed are the by-hand method, which involves manual calculations using certain summaries and formulas, and the calculator method, which uses a calculator to compute the regression line more efficiently.
What is the least square regression line used for?
-The least square regression line is used for predicting y values (y hat) from a given x value in a bivariate data set.
Why is it important to understand the formulas for the least square regression line rather than just memorizing them?
-It is important to understand the formulas to know what they are doing for you and how to utilize them effectively, rather than just memorizing them for the sake of a test or homework.
What is the correlation coefficient (r) and what is its range?
-The correlation coefficient (r) measures the strength and direction of the linear relationship between x and y. It ranges from -1 to 1, with -1 indicating a perfect negative linear relationship, 1 indicating a perfect positive linear relationship, and 0 indicating no linear relationship.
What is the purpose of constructing a scatter plot for bivariate data?
-A scatter plot is used to visually assess the linear association between x and y, which can then be verified by calculating the correlation coefficient (r).
What is the significance of the critical value in determining linear association?
-The critical value, found in table two, is used to determine if the absolute value of the correlation coefficient is significant enough to claim a linear association. If the absolute value of r is greater than the critical value, a linear association is confirmed.
How is the slope (b1) of the least square regression line calculated in the by-hand method?
-The slope (b1) is calculated as the correlation coefficient (r) multiplied by the ratio of the standard deviation of y's to the standard deviation of x's.
What is the coefficient of determination (r squared) and how is it used?
-The coefficient of determination (r squared) measures the proportion of the total variation in the response variable that is explained by the least square regression line. It is used to assess the quality of the model and to compare different models.
Why is it incorrect to use the least square regression line for predicting values of x outside the range of the collected data?
-Using the least square regression line for predicting values of x outside the range of the collected data is incorrect because it is an act of extrapolation. The linear relationship may not hold outside the observed range, leading to unreliable predictions.
What is the difference between an observational study and a designed experiment?
-An observational study is one where responses are measured without any attempt to control for external factors, simply observing the data as it is. A designed experiment, on the other hand, uses randomization to control for possible external factors by randomly assigning individuals to explanatory values and observing the responses. Only designed experiments allow for the claim of causation.
What is a lurking variable or confounding variable, and why is it important in the context of correlation?
-A lurking variable or confounding variable is a factor that is related to both the explanatory and response variables and can affect the observed correlation. It is important because it can drive the changes seen in the data, making it difficult to determine causation. Only through a designed experiment with random assignment can confounding variables be controlled for.
Outlines
📚 Resuming Bivariate Data Discussion
The instructor continues the lesson on bivariate data analysis from the previous class, focusing on chapter four's second half. The aim is to further explore the concepts introduced earlier, specifically the least squares regression line for predicting y-values from given x-values. The importance of understanding the formulas for slope and y-intercept is emphasized, along with the reminder that these formulas will be provided and are not required to be memorized. The instructor also revisits the necessity of five summary statistics for manual calculation of the regression line and the significance of the correlation coefficient (r) in determining linear association, cautioning against its misuse outside of linear relationships.
🔍 Delving into Least Squares Regression Line Calculation
This section provides a step-by-step example of calculating the least squares regression line by hand, using the provided data on parental income and children's IQs. The instructor demonstrates how to derive the slope (b1) and y-intercept (b0) using the given averages, standard deviations, and the correlation coefficient. The calculated model is then used to predict a child's IQ based on a specific parental income. The instructor also discusses the limitations of this model, noting that a low r-value indicates a weak association and suggesting that other factors beyond parental income influence a child's IQ.
📈 Utilizing Technology for Regression Analysis
The instructor shifts the focus to using a calculator for regression analysis, starting with constructing a scatter plot from a given data set to visually assess the relationship between x and y. The correlation coefficient is calculated to verify the linear association suggested by the scatter plot. The least squares regression line is then derived using calculator functions, and the model's parameters, including the slope and y-intercept, are discussed. The r-squared value is introduced as a measure of how well the model fits the data, and a prediction is made using the derived model for a given x-value.
🤔 Questioning the Best Fit Model
The instructor poses a question about whether the least squares regression line is the best possible model for the data set, clarifying that while it is the best linear model, there may be other models, such as quadratic, that fit the data better. The concept of sum of squared residuals is introduced as a criterion for model fitness, and the instructor demonstrates how to use a calculator to perform quadratic regression, highlighting the improved fit of the quadratic model over the linear one.
📉 Understanding the Limitations of Correlation
This section discusses the limitations of the correlation coefficient, emphasizing that it only describes the strength and direction of a linear relationship and is not applicable to other types of relationships. The instructor also addresses the impact of outliers in bivariate data sets, referred to as influential points, which can significantly affect the slope and y-intercept of the regression line. The importance of calculating the regression line with and without influential points to understand their impact is highlighted.
⚠️ Avoiding Extrapolation in Predictions
The instructor warns against the practice of extrapolation, which is making predictions for x-values outside the range of the collected data. Using the real estate data example, the instructor demonstrates how using the regression model outside its valid range can lead to unreliable predictions. The importance of staying within the range of observed data when making predictions is emphasized to avoid erroneous results.
🔑 The Coefficient of Determination
The instructor introduces the coefficient of determination (r-squared) as a measure of how well the regression line describes the relationship between x and y. It is calculated by squaring the correlation coefficient and represents the proportion of the total variation from the average in y that is explained by the regression line. The instructor illustrates this concept using the real estate data example, showing that 81% of the variation in selling price is explained by the square footage of the houses.
🚫 Correlation Does Not Imply Causation
The instructor concludes with a cautionary note about mistaking correlation for causation. Even with a high correlation coefficient, one cannot conclude that changes in x cause changes in y without a designed experiment. Observational studies can only indicate association, not causation. The instructor uses a hypothetical example involving shoe size and vocabulary aptitude in children to illustrate the absurdity of assuming causation from correlation and emphasizes the need for randomization in experiments to claim causation.
Mindmap
Keywords
💡Bivariate Data
💡Least Squares Regression Line
💡Correlation Coefficient (r)
💡Standard Deviation
💡Slope (b1)
💡Y-Intercept
💡Critical Value
💡R-Squared (R²)
💡Outliers
💡Extrapolation
💡Coefficient of Determination
💡Observational Study
💡Causation
💡Designed Experiment
Highlights
Continuation of the bivariate data discussion from the previous lesson, focusing on the least squares regression line.
Introduction of two methods for calculating the least squares regression line: by hand and using a calculator.
Explanation of the importance of understanding the formulas for the least squares regression line rather than memorizing them.
Discussion on the five summaries necessary for generating the least squares regression line by hand.
Clarification that the correlation coefficient, r, is only used for linear association and its limitations.
Introduction of the concept of critical values for the correlation coefficient to claim linear association.
Example of calculating the least squares regression line by hand using data from a study on parental income and children's IQ.
Explanation of the limitations of the model in predicting children's IQ based on parental income due to a low r value.
Demonstration of using a calculator to find the least squares regression line and the importance of constructing a scatter plot first.
Process of calculating the correlation coefficient using a calculator and interpreting its value.
Introduction of the concept of R-squared as a measure of how well the regression line describes the relationship between variables.
Comparison of R-squared values for linear and quadratic models to determine which model fits the data better.
Discussion on the limitations of the correlation coefficient and its inability to describe non-linear relationships.
Caution against using the least squares regression line for extrapolation beyond the range of the data collected.
Explanation of the coefficient of determination and its role in indicating the quality of the model for prediction.
The difference between observational studies and designed experiments, and the importance of randomization in claiming causation.
Highlighting the danger of mistaking correlation for causation without proper experimental design.
Final thoughts on the importance of understanding the limitations of regression models and the need for proper study design.
Transcripts




5.0 / 5 (0 votes)
Thanks for rating: