Introduction to Statistics
TLDRThe video provides an introduction to statistics, covering how to calculate and interpret mean, median, mode, range, quartiles, interquartile range, outliers, box plots, skewness, dot plots, stem & leaf plots, frequency tables and histograms from a dataset. It explains how to identify symmetric vs skewed distributions, construct tables to find relative frequencies and percentiles, and determine if numbers are outliers. Examples and step-by-step working are provided to demonstrate these statistical concepts and methods clearly.
Takeaways
- 😀 How to calculate mean, median, mode and range of a dataset
- 📊 How to construct a box plot and identify outliers
- 📈 Concepts of data skewness, positive and negative skew
- 🎯 How to make a stem and leaf plot and dot plot
- 📋 Creating frequency tables and histograms
- 🔢 Calculating relative and cumulative frequencies
- 👌 Finding percentiles from a frequency distribution
- 📒 Constructing frequency distribution tables
- 🗂️ Organizing data into classes and intervals
- 🖥️ Using Excel to analyze and visualize data
Q & A
How do you calculate the mean of a data set?
-To calculate the mean, take the sum of all the numbers in the data set and divide it by the total number of data points. For example, if the data set is {7, 7, 10, 14, 15, 23, 32}, the sum is 108 and there are 7 numbers. 108/7 = 15.43.
What is the difference between a bar graph and a histogram?
-A bar graph and histogram are very similar, but the bars in a histogram are adjacent to each other with no spaces in between. The bars in a bar graph are spaced out.
How do you identify if a number is an outlier in a data set?
-To identify if a number is an outlier, calculate the range using: Q1 - 1.5*IQR as the lower bound, and Q3 + 1.5*IQR as the upper bound. If a number in the data set falls outside this range, it is considered an outlier.
What are the key components of a box and whisker plot?
-The key components of a box and whisker plot are: the minimum, first quartile (Q1), median (second quartile/Q2), third quartile (Q3), maximum, and outliers shown as points outside the box.
How can you identify if a distribution is skewed to the left or right?
-If the shape of the data distribution has a longer tail extending to the right, it is positively or right skewed. If the tail extends further to the left, it has a negative or left skew.
What is the difference between a stem-and-leaf plot and a dot plot?
-In a stem-and-leaf plot, the data values are split into a stem digit and a leaf digit to create a tabular summary. In a dot plot, dots are used above a number line to show each data value.
What are quartiles and how are they useful?
-Quartiles divide an ordered data set into four equal groups. The first quartile (Q1) represents 25% of the data, second quartile (Q2) is 50% and third quartile (Q3) is 75%. Quartiles are useful for identifying distribution shapes and outliers.
How do you construct a frequency table?
-To construct a frequency table, list each unique data value in one column. In a second column, tally the frequency or count of occurrences for each value. Sum the frequencies to get the total number of data points.
What is relative frequency and cumulative relative frequency?
-Relative frequency is each frequency divided by the total count. Cumulative relative frequency sums the relative frequencies cumulatively to show the proportion below each data value.
What is the purpose of a stem-and-leaf plot?
-A stem-and-leaf plot organizes data by splitting each value into a stem digit and a leaf digit. This allows the shape of the distribution to be visualized and makes it easy to see clusters and gaps.
Outlines
😊 Overview of statistical concepts
This paragraph provides an overview of key statistical concepts that will be covered, including calculating the mean, median, mode, range, quartiles, interquartile range, outliers, box plots, skewness, dot plots, stem and leaf plots, frequency tables, histograms, and relative frequencies.
😃 Calculating statistical measures
This paragraph demonstrates how to calculate the mean, median, mode, and range for two sample data sets. It explains the process step-by-step.
😃 Finding quartiles and interquartile range
This paragraph explains how to find the first, second, and third quartiles (Q1, Q2, Q3) of a data set in order to determine the interquartile range. It also shows how to identify outliers.
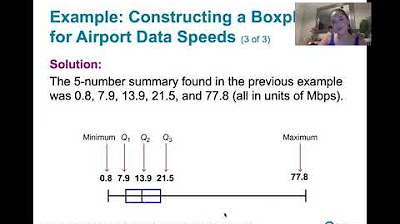
😃 Constructing a box plot
This paragraph discusses the components of a box plot and demonstrates how to construct one using the statistical measures calculated from a data set, including quartiles and outliers.
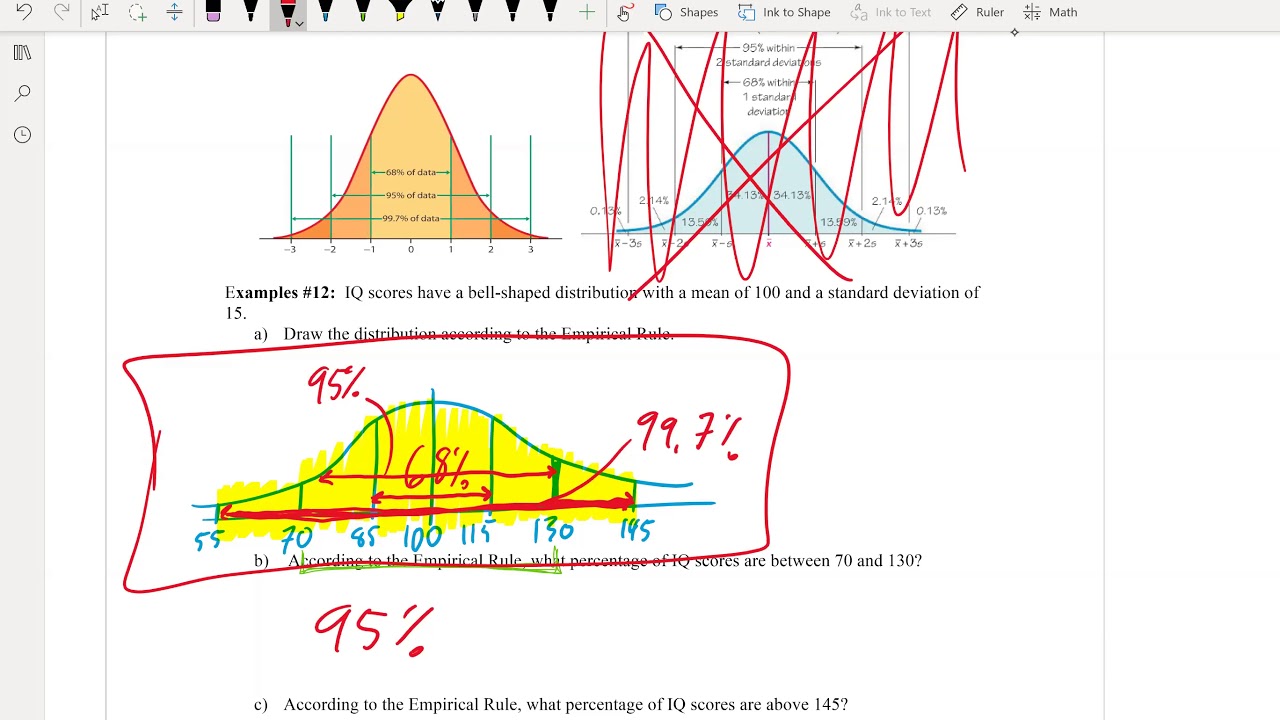
😃 Identifying skewed distributions
This paragraph differentiates between symmetric, positively skewed, and negatively skewed distributions. It relates skewness to the position of the mean relative to the median.
😃 Additional statistical representations
This paragraph briefly covers creating other types of statistical plots and tables, including dot plots, stem and leaf plots, frequency tables, and histograms.
😃 Using frequency tables
This paragraph shows how a frequency table summarizes a data set and can be used to efficiently calculate the mean.
😃 Constructing a stem and leaf plot
This paragraph provides two examples of creating stem and leaf plots from data sets, including plots for decimal values.
😃 Building a frequency table
This paragraph demonstrates the process of constructing a frequency table to show the distribution of values in a data set.
😃 Creating histograms
This paragraph explains the difference between histograms and bar graphs. It shows how to create a histogram using a frequency distribution table.
😃 Calculating relative frequencies
This paragraph shows how to augment a frequency table by adding columns for relative frequency and cumulative relative frequency in order to determine percentiles.
😃 Understanding percentiles visually
This paragraph explains how to determine percentiles from a cumulative relative frequency table. It also provides a visual representation to build intuition.
Mindmap
Keywords
💡Statistics
💡Mean
💡Median
💡Mode
💡Range
💡Quartiles
💡Interquartile Range
💡Outlier
💡Skewness
💡Histogram
Highlights
To find mean, median, mode, and range, first arrange data in order, then calculate each value using specific formulas.
Median is middle number when data arranged in order. Eliminate outer numbers until reach middle.
Mode is number that occurs most frequently in data set.
Range is difference between highest and lowest numbers.
To find quartiles and interquartile range, divide ordered data into 4 equal sections. Q1 and Q3 are medians of lower and upper halves.
Interquartile range (IQR) is difference between Q3 and Q1. Use to identify outliers.
Symmetrical distribution has mean = median. Skewed right distribution has mean > median. Skewed left has mean < median.
Box plots visually show quartiles and outliers. Position of Q2 indicates skewness.
Dot plots place dots above values on number line based on frequency in data set to visualize distribution.
Stem-and-leaf plots separate out digits of each number to provide overview of distribution in compact table format.
Frequency tables tally counts per unique number to enable calculations like mean.
Histograms use adjacent bars representing ranges of values to show distribution.
Relative frequency normalizes counts by total data points. Cumulative relative frequency used to find percentiles.
Percentiles identify value below which given percentage of data exists, using cumulative relative frequencies.
Visual representation shows correspondence between percentiles and location within ordered data set distribution.
Transcripts
Browse More Related Video




5.0 / 5 (0 votes)
Thanks for rating: