Measures of Central Tendency (Mean, Median, Mode)
TLDRThis video introduces measures of central tendency, including the mean, median, and mode. It explains the importance of mathematical notation for understanding these concepts, especially as analyses become more complex. The video details how to calculate the population and sample means, the median, and the mode, emphasizing the influence of skewed data on these measures. Examples are provided to illustrate these points, highlighting the pros and cons of each measure and when they are most appropriately used.
Takeaways
- 📚 Measures of central tendency are statistical measures that represent the center or middle of a data distribution.
- 🔢 The mean is calculated as the sum of all scores in a set divided by the total number of scores.
- 📐 The notation for population mean is the Greek letter mu (μ), while for sample mean it's x-bar (x̄) or capital M.
- 📚 The formula for population mean is μ = ΣXi / N, where Xi represents each score and N is the total number of scores.
- 📝 The formula for sample mean is similar to the population mean but uses x̄ to represent the mean and n for sample size.
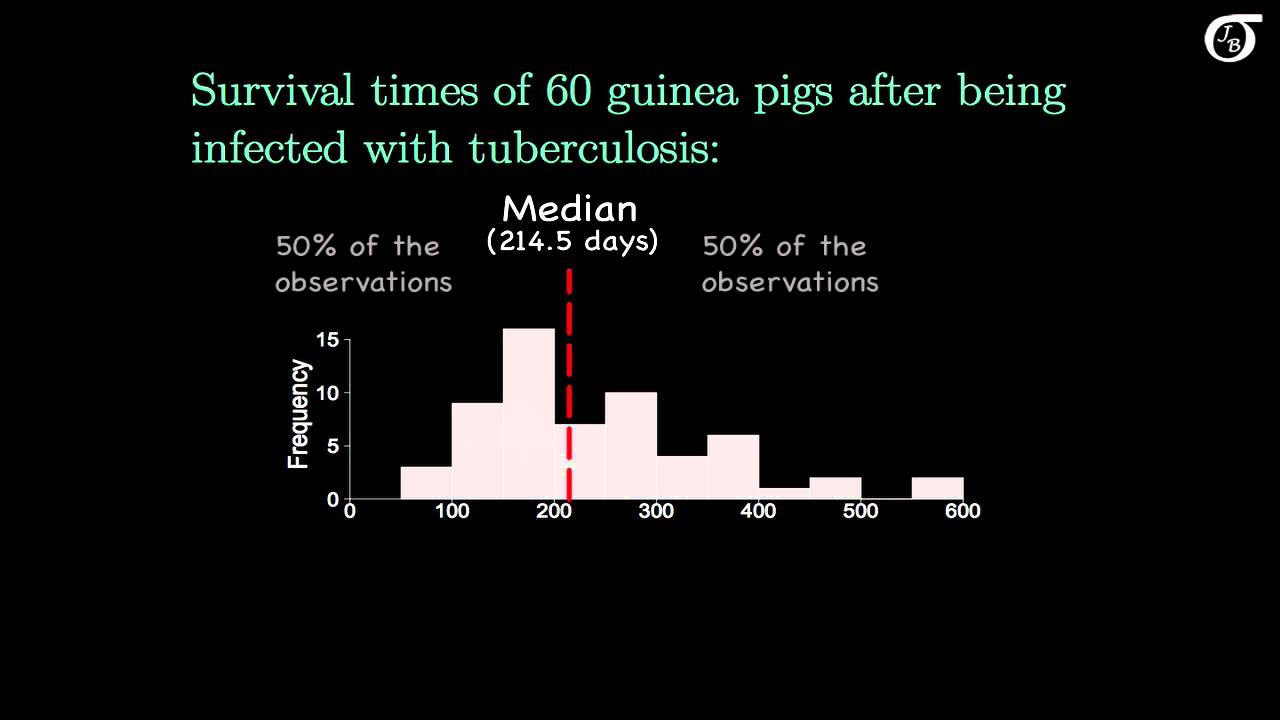
- 🏁 The median is the middle value in a data set when the values are arranged in ascending or descending order.
- 🌟 The mode is the value that occurs most frequently in a data set and can be calculated even with non-numeric data.
- 📉 In a normal distribution (bell curve), the mean, median, and mode are all equal.
- 📈 The mean is heavily influenced by skew and outliers, while the median is moderately influenced, and the mode is relatively immune.
- 📊 Skewed distributions can cause the mean, median, and mode to differ significantly, with the mean being particularly susceptible to extreme values.
- 📋 It's important to consider the pros and cons of each measure of central tendency and choose the most appropriate one based on the data set's characteristics.
Q & A
What are measures of central tendency?
-Measures of central tendency are numbers that represent the center or middle of a distribution of data. They include the mean, median, and mode.
What is the mean and how is it calculated?
-The mean is the average of a set of scores. It is calculated by summing all the numbers in the dataset and then dividing by the total number of scores.
What are the symbols used for the population mean and sample mean?
-The symbol for the population mean is the Greek letter mu (μ), while the sample mean can be represented by x-bar (x̄) or capital M.
What is the formula for calculating the population mean?
-The formula for the population mean is μ = ΣXi / N, where ΣXi represents the sum of all scores in the dataset and N is the total number of scores.
What is the difference between the population mean and sample mean?
-The population mean (μ) represents the average of an entire population, while the sample mean (x̄) is the average of a subset of that population.
What is the median and how is it found?
-The median is the middle value in a dataset when the values are listed in ascending or descending order. If there is an even number of values, the median is the average of the two middle numbers.
What is the mode and how is it different from the mean and median?
-The mode is the value that occurs most frequently in a dataset. Unlike the mean and median, the mode can be used with non-numerical data and is not influenced by outliers.
Why is the mode considered to be immune to skew?
-The mode is immune to skew because it is determined by the most frequently occurring value in the dataset, regardless of the distribution's shape or the presence of outliers.
How are the mean, median, and mode affected by a skewed distribution?
-In a skewed distribution, the mean is heavily influenced by the skew, the median is moderately influenced, and the mode remains relatively unaffected.
What is an example of how the mean can be influenced by an extreme outlier?
-In the provided example, adding an extreme outlier like 1,000 to the dataset of 1, 1, 3, 3, 3, 4 significantly increases the mean, showing its susceptibility to outliers.
Why might the median and mode be better measures of central tendency than the mean in certain situations?
-The median and mode can be better measures of central tendency when the dataset is skewed or contains outliers, as they provide a more accurate reflection of the middle of the dataset.
Outlines
📊 Introduction to Measures of Central Tendency
This paragraph introduces the concept of measures of central tendency, which are statistical measures that represent the center or middle of a data distribution. The speaker explains that while mathematical symbols may seem unnecessary for simple concepts like the mean, they become increasingly important for more complex analyses. The mean is defined as the sum of all scores in a set divided by the total number of scores. The notation for the mean differs between populations (using the Greek letter mu) and samples (using x-bar or capital M). The formula for calculating the population mean (μ = ΣX_i / N) and the sample mean (x̄ = ΣX_i / n) is provided, with an explanation of the symbols used. The paragraph also briefly mentions the median and mode as other measures of central tendency, with the median being the middle value in an ordered set and the mode being the most frequently occurring value.
🔢 Understanding the Mean, Median, and Mode
The second paragraph delves deeper into the characteristics and differences between the mean, median, and mode. It explains that the mode can be calculated even with non-numerical data, as illustrated with a dataset of beverage orders where 'espresso' is the mode due to its highest frequency of occurrence. The paragraph also discusses the impact of data distribution skewness on these measures. In a normal (bell curve) distribution, the mean, median, and mode are equal. However, in skewed distributions, these measures can differ significantly. The mean is heavily influenced by skew and outliers, the median is moderately affected, and the mode is relatively immune to skew. An example is provided where a dataset with an extreme outlier (1,000) significantly raises the mean but does not affect the median and mode as much. The importance of considering the pros and cons of each measure of central tendency when analyzing data is emphasized.
Mindmap
Keywords
💡Measures of Central Tendency
💡Mean
💡Median
💡Mode
💡Notation
💡Population
💡Sample
💡Skewed Distribution
💡Outliers
💡Sum of Scores
Highlights
Introduction to measures of central tendency, including mean, median, and mode.
Explanation of the mean as the sum of scores divided by the total number of scores.
Differentiation between population parameters (mu) and sample statistics (x-bar or M).
Presentation of the formula for calculating the population mean.
Clarification on the use of Greek letters for population parameters and English letters for sample statistics.
Introduction to the formula for calculating the sample mean with x-bar notation.
Importance of distinguishing between population size (capital N) and sample size (little n).
Definition of the median as the middle value in a data set.
Explanation of the mode as the most frequently occurring value in a data set.
Illustration of calculating the mode with a non-numeric data set example.
Comparison of the mean, median, and mode in a normal distribution (bell curve).
Discussion on the influence of skewness on the mean, median, and mode.
Example of a negatively skewed distribution and its effect on central tendency measures.
Example of a positively skewed distribution and how it impacts the mean, median, and mode.
Highlighting the mean's susceptibility to extreme values or outliers.
Demonstration of how an outlier can significantly affect the mean in a given data set.
Comparison of the mean, median, and mode in a data set with an extreme outlier.
Recommendation to consider the pros and cons of each measure of central tendency.
Transcripts
Browse More Related Video

Mean, Median, Mode, and Outliers: Measures of Central Tendency
Measures of Central Tendency

Mean, Median and Mode in Statistics | Statistics Tutorial | MarinStatsLectures

Mean, Median, and Mode: Measures of Central Tendency: Crash Course Statistics #3

What is Central Tendency – An Introduction to Mean, Median, and Mode in Statistics (5-1)

Understanding Central Tendency
5.0 / 5 (0 votes)
Thanks for rating: