Measures of Dispersion (Ungrouped Data) | Basic Statistics
TLDRThis educational video delves into the concepts of range, variance, and standard deviation as measures of dispersion in a set of data. Using an example dataset, the presenter illustrates the importance of these statistical tools for understanding the spread and variability of data points. The video provides step-by-step instructions on calculating the range, variance, and standard deviation, emphasizing the difference between sample and population variance. It demonstrates the process of finding the mean, aligning data, and performing calculations to arrive at the measures of dispersion, ultimately helping viewers grasp how these values can reveal the nature of a dataset's distribution.
Takeaways
- 📊 The video discusses range, variance, and standard deviation as measures of dispersion or variation for a set of data.
- 🔢 The example data set provided is 1, 2, 4, 7, 9, and 12, which will be used to calculate the range, variance, and standard deviation.
- 📚 Measures of dispersion are important because they provide insight into how spread out the numbers are from the mean, beyond just knowing the mean itself.
- 🌐 The concept of dispersion is illustrated with examples of different data sets having the same mean but varying degrees of spread.
- 📐 The range is calculated as the difference between the highest and lowest values in the data set, providing a rough estimation of dispersion.
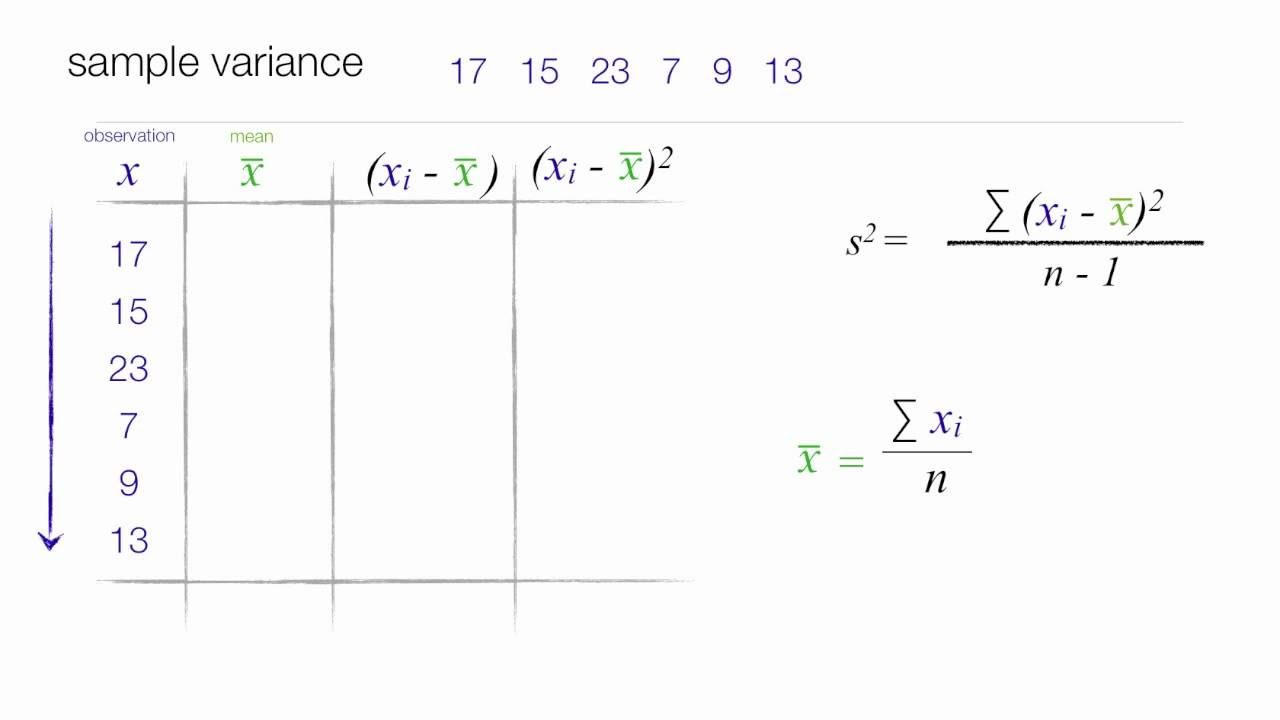
- ⚖️ Variance is a more accurate measure of dispersion, calculated as the sum of the squared differences from the mean, divided by the number of data points minus one.
- 📐 The standard deviation is the square root of the variance, indicating the average distance of data points from the mean.
- 🧮 The mean of a data set is calculated by summing all values and dividing by the number of values, which is essential for calculating variance and standard deviation.
- 📝 The process involves aligning the data, calculating the difference from the mean (X - mean), squaring these differences, and then using these to find the variance and standard deviation.
- 📉 The video provides a step-by-step guide to calculating the range, variance, and standard deviation for the given example data set.
- 📚 The importance of understanding dispersion in data is emphasized, as it helps in gaining a clearer picture of the data's distribution.
Q & A
What are the measures of dispersion discussed in the video?
-The measures of dispersion discussed in the video are range, variance, and standard deviation. These measures help to understand how spread out the numbers in a dataset are from the center.
Why is it important to know the dispersion of a dataset?
-Knowing the dispersion of a dataset is important because it provides a more complete picture of the data's distribution. It helps to understand how scattered the numbers are and gives insights into the dataset's variability beyond just the mean.
What is the formula for calculating the range of a dataset?
-The formula for calculating the range of a dataset is the highest value minus the lowest value (highest - lowest). This gives a rough estimation of the spread of the data.
What is the difference between sample variance and population variance?
-Sample variance is calculated using a subset of data (sample) and is denoted by S^2, while population variance is calculated using the entire dataset. The formula for sample variance involves dividing by n-1 (number of data points minus one), whereas population variance divides by n (the total number of data points).
How is standard deviation related to variance?
-Standard deviation is the square root of the variance. It provides a measure of dispersion that is in the same units as the data, making it easier to interpret compared to variance, which is in squared units.
What is the formula for calculating the mean of a dataset?
-The formula for calculating the mean of a dataset is the sum of all the values divided by the number of values (sum of values / number of values).
How does the video illustrate the concept of dispersion with different datasets having the same mean?
-The video uses three different datasets (1, 2, 4, 7, 9, 12; 2, 8, 9, 10, 11, 12; and 4, 7, 10, 13, 16) that all have a mean of 10 to illustrate that having the same mean does not necessarily mean the datasets have the same dispersion. The dispersion varies significantly among these datasets.
What is the purpose of arranging the data from smallest to largest before calculating measures of dispersion?
-Arranging the data from smallest to largest is not a requirement for calculating measures of dispersion. However, it can help visualize the spread of the data and make it easier to identify the highest and lowest values for range calculation.
Why is it not advisable to round off intermediate values when calculating measures of dispersion?
-Rounding off intermediate values during the calculation process can introduce errors that affect the final result. It's important to use exact values until the final answer is obtained to ensure accuracy.
How does the video demonstrate the calculation of variance and standard deviation for the given dataset?
-The video demonstrates the calculation by first finding the mean, then creating a column for the difference between each data point and the mean (X - mean), squaring these differences, summing them up, and finally dividing by n-1 to find the variance. The standard deviation is then found by taking the square root of the variance.
Outlines
📊 Introduction to Measures of Dispersion
This paragraph introduces the concepts of range, variance, and standard deviation as measures of dispersion for a set of data. It explains that these measures indicate how spread out the numbers are from the mean, which is crucial for understanding the data's distribution. The example set of numbers (1, 2, 4, 7, 9, 12) is presented, and the importance of dispersion measures over just knowing the mean is highlighted. The paragraph also illustrates the concept with different sets of data that have the same mean but different levels of dispersion.
🔢 Calculating Range and Variance
The second paragraph delves into the calculation of the range and variance for the given data set. The range is defined as the difference between the highest and lowest values, which provides a rough estimate of dispersion. The formula for range is presented, and the calculation for the example data is shown, resulting in a range of 11. The paragraph then moves on to explain variance, which is a more accurate measure of dispersion. The formula for sample variance (S²) is introduced, and the process of calculating variance is described step by step, including finding the mean of the data set, which is approximately 5.83.
📐 Detailed Steps for Computing Variance and Standard Deviation
This paragraph provides a detailed walkthrough of the steps to compute variance and standard deviation. It starts by arranging the data set and creating a column for the difference between each data point and the mean (X - mean). The next step involves squaring these differences and summing them up. The sum of the squared differences is then divided by the number of data points minus one to find the variance. The standard deviation is derived by taking the square root of the variance. The paragraph emphasizes the importance of using exact values during calculations and rounding off only at the final step.
📚 Conclusion and Call to Action
The final paragraph wraps up the video by summarizing the process of finding the standard deviation, which is the square root of the variance. It reiterates that the standard deviation provides a measure of how spread out the data is from the mean. The paragraph concludes with a call to action, encouraging viewers to subscribe to the channel and leave comments about the mathematical topics they wish to learn more about, fostering engagement with the audience.
Mindmap
Keywords
💡Range
💡Variance
💡Standard Deviation
💡Measures of Dispersion
💡Mean
💡Ungrouped Data
💡Sample Variance
💡Population Variance
💡Dispersion
💡Data Set
Highlights
Introduction to range variance and standard deviation as measures of dispersion for a set of data.
Explanation of how range variance and standard deviation measure the spread of numbers from the center.
Illustration of the concept of measures of dispersion using hypothetical data sets with a mean of 10.
Importance of knowing the dispersion of data beyond just the mean for a comprehensive understanding.
Demonstration of how different data sets with the same mean can have varying degrees of dispersion.
Introduction to the range as a rough estimation of data dispersion.
Formula for calculating the range: highest value minus the lowest value.
Explanation of variance as a more accurate measure of data dispersion than range.
Formula for calculating sample variance using the sum of squared differences from the mean.
Introduction to standard deviation as the square root of variance.
Formula for calculating the mean of a data set as the sum of values divided by the number of values.
Step-by-step process for aligning data, calculating x-mean, and squaring the differences.
Explanation of the importance of using exact values when calculating x-mean and its square.
Summation of squared differences from the mean to use in the variance formula.
Calculation of variance using the formula and the sum of squared differences.
Derivation of standard deviation by taking the square root of the variance.
Final values for variance and standard deviation from the example data set.
Conclusion and encouragement to subscribe for more math topics.
Transcripts
Browse More Related Video

Statistics: Standard deviation | Descriptive statistics | Probability and Statistics | Khan Academy

Range, variance and standard deviation as measures of dispersion | Khan Academy

Measures of Spread & Variability: Range, Variance, SD, etc| Statistics Tutorial | MarinStatsLectures
How to calculate Standard Deviation and Variance
Mode, Median, Mean, Range, and Standard Deviation (1.3)

Understanding Standard deviation and other measures of spread in statistics
5.0 / 5 (0 votes)
Thanks for rating: