Mean and standard deviation versus median and IQR | AP Statistics | Khan Academy
TLDRThe video script discusses the concept of central tendency and spread in the context of nine graduates' salaries. It highlights the limitations of mean and standard deviation when dealing with skewed data, such as the presence of an outlier (a $250,000 salary). Instead, the median and interquartile range are presented as more robust measures for skewed datasets, as they are less affected by extreme values, providing a more accurate representation of the central tendency and spread of the data.
Takeaways
- 🎓 The scenario involves nine students from a small school who want to understand the central tendency and spread of their salaries one year after graduation.
- 💰 The students' salaries range from $35,000 to $250,000, showing a wide disparity and skewness in the data distribution.
- 📊 The mean (average) salary calculated is approximately $76,200, which is significantly influenced by the outlier of $250,000.
- 🔢 The median salary is $56,000, which is a more representative value for the central tendency of this skewed data set.
- 📈 A visual representation of the data shows that the mean is higher than most data points except for the outlier, highlighting its limitation in representing the central tendency accurately.
- 🤔 The video encourages viewers to consider which measure of central tendency is more appropriate for understanding the data set, concluding that the median is better suited for skewed data.
- 📊 The interquartile range (IQR) is introduced as a robust measure of spread that is not affected by outliers, calculated as the difference between the 75th percentile and the 25th percentile.
- 📈 The IQR in this case is $17.5, demonstrating that it remains consistent even if the outlier value changes drastically, making it a reliable measure of spread.
- 🏠 The script mentions that median salary and home prices are often reported in public discussions to avoid the skewing effect of outliers, which can provide a false impression of the average.
- 📝 The video script is a review of statistical concepts such as mean, median, standard deviation, and interquartile range, emphasizing their applications and limitations in data analysis.
- 👍 The key takeaway is that while mean and standard deviation are useful for symmetric data sets without significant outliers, median and interquartile range are more appropriate for skewed data sets.
Q & A
What is the central tendency the nine students want to determine for their salaries one year after graduation?
-The nine students want to determine the central tendency, or the typical value that best represents the salary data for their group one year after graduation.
How many students make a salary of 50,000 and what is the mean salary calculated by the computer?
-Three students make a salary of 50,000. The mean salary calculated by the computer is approximately 76.2 thousand dollars.
What is the median salary for the group and how is it calculated?
-The median salary for the group is 56 thousand dollars. It is calculated by ordering the salaries and taking the middle value, which in this case is 56 thousand dollars.
Why might the mean salary not be a good measure of central tendency for this data set?
-The mean salary might not be a good measure of central tendency for this data set because it is skewed by the outlier of 250,000 dollars, which makes the mean higher than all data points except for one.
How does the narrator suggest the median is a more robust measure than the mean in this context?
-The narrator suggests that the median is more robust because it is not affected by the outlier and provides a more accurate representation of the central tendency for the group's salary data.
What is the interquartile range and how is it calculated?
-The interquartile range is a measure of the spread of the salary data. It is calculated by taking the difference between the median of the upper half of the data (75 thousand dollars) and the median of the lower half of the data (50 thousand dollars), resulting in a range of 25 thousand dollars.
Why is the interquartile range a better measure of spread for skewed data sets?
-The interquartile range is a better measure of spread for skewed data sets because it is not affected by outliers. It represents the middle 50% of the data, providing a more accurate picture of the typical spread around the central tendency.
What does the script suggest about using the median and interquartile range in salary discussions?
-The script suggests that the median and interquartile range are often used in salary discussions because they provide a more accurate representation of typical salaries without being skewed by extremely high or low values.
How does the presence of an outlier affect the standard deviation in this context?
-The presence of an outlier, such as the 250,000 dollar salary, affects the standard deviation by skewing it and making it larger than it would be if the data set were more evenly distributed. This can give a false impression of the typical spread of salaries.
What is the significance of discussing central tendency and spread in the context of salary data?
-Discussing central tendency and spread in the context of salary data is significant because it helps to understand the typical earnings and the range of earnings within a group or population. This is important for making informed decisions and comparisons related to compensation and employment.
Why is it important to consider the robustness of statistical measures when dealing with skewed data?
-It is important to consider the robustness of statistical measures when dealing with skewed data because non-robust measures can be heavily influenced by outliers, leading to a distorted understanding of the data. Using robust measures like the median and interquartile range provides a more accurate and reliable representation of the data.
Outlines
📊 Analyzing Central Tendency in Skewed Salary Data
This paragraph discusses the concept of central tendency, specifically in the context of a skewed salary dataset. It describes a scenario where nine students, who recently graduated, input their salaries into a computer to determine the mean and median. The mean salary is calculated to be 76.2 thousand, while the median is 56 thousand. The narrator points out the influence of an outlier (a salary of 250 thousand) on the mean, making it less representative of the group's central tendency. The median is highlighted as a more robust measure in such cases, as it is not affected by extreme values. The paragraph also touches on the visual representation of the data, emphasizing the importance of understanding the distribution of salaries relative to each other.
📈 Choosing the Right Measure for Skewed Data: Median and Interquartile Range
The second paragraph continues the discussion on data analysis, focusing on the measures of spread. It questions the reliability of standard deviation when the mean is not a good measure of central tendency due to skewness in the data. The interquartile range (IQR) is introduced as a more robust alternative to standard deviation for indicating the spread of the data. The IQR is calculated by finding the median of the lower and upper halves of the dataset, resulting in a value of 17.5 in this case. The paragraph emphasizes that the IQR remains unaffected by extreme values, making it a suitable measure for skewed datasets. It concludes by noting that while mean and standard deviation are suitable for symmetric datasets without significant outliers, median and IQR are preferable for skewed data, such as salary and home price distributions.
Mindmap
Keywords
💡central tendency
💡salaries
💡spread
💡mean
💡median
💡outlier
💡interquartile range
💡skewness
💡standard deviation
💡data set
💡robustness
Highlights
Nine students from a small school with a class size of nine want to understand the central tendency and spread of their salaries one year after graduation.
The students input their salaries into a computer to get statistical parameters.
The mean salary calculated is approximately 76.2 thousand dollars, which is influenced by the outlier of 250 thousand dollars.
The median salary is 56 thousand dollars, which is a more accurate representation of the central tendency for this skewed data set.
A visual representation of the salary data helps to understand the skewness and the impact of the outlier.
The mean can be skewed by extreme values, making it less reliable for skewed data sets.
The median is more robust and provides a better measure of central tendency for skewed data.
Changing the outlier value, even to an extreme like 250 million dollars, does not affect the median.
The interquartile range is a robust measure of spread, calculated by finding the median of the lower and upper halves of the data set.
The interquartile range remains unchanged even with extreme values, making it a reliable measure for skewed data.
Mean and standard deviation can be reliable measures for symmetric data sets without significant outliers.
Median and interquartile range are preferred for skewed data sets, especially when discussing salaries and home prices.
In the context of salaries, the presence of high earners can skew the mean, making the median a more accurate reflection of typical earnings.
Home prices in a city can also be skewed by a few extremely high-value properties, making the median a more representative measure.
Understanding the difference between mean, median, and interquartile range is crucial for accurately interpreting statistical data.
The example of the nine students' salaries illustrates the importance of choosing the right measure of central tendency and spread for the data set in question.
In practical applications, such as salary negotiations or real estate, being aware of the impact of outliers is essential for making informed decisions.
Transcripts
Browse More Related Video
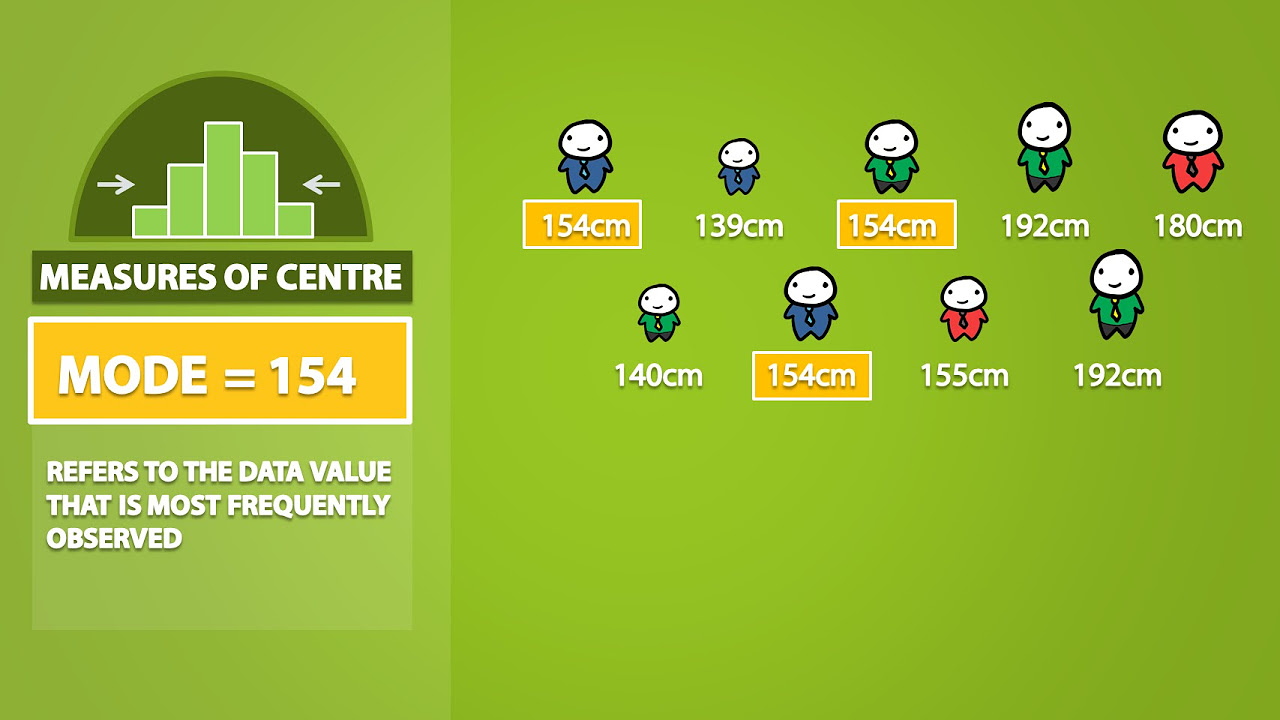
Mode, Median, Mean, Range, and Standard Deviation (1.3)

What is Variability? – An Introduction to Variance in Statistics (6-1)
Mean, Median and Mode - Measures of Central Tendency

Mean, Median and Mode in Statistics | Statistics Tutorial | MarinStatsLectures

Range, variance and standard deviation as measures of dispersion | Khan Academy
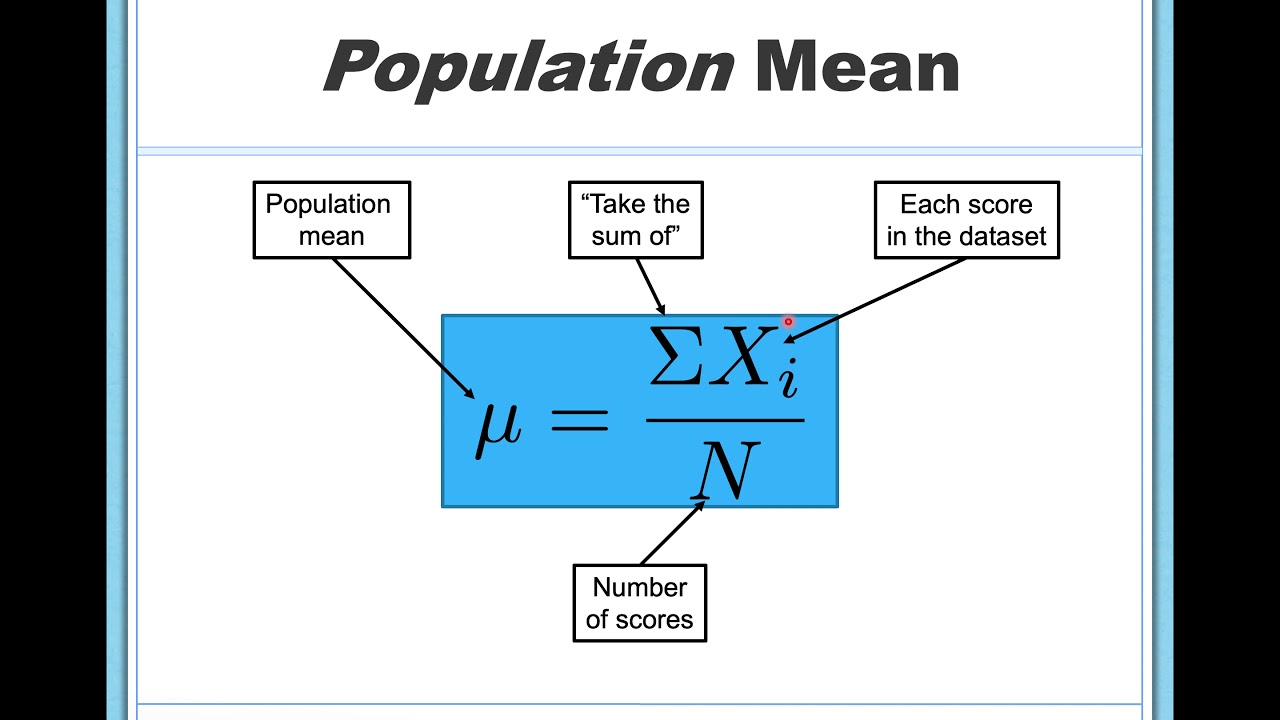
Measures of Central Tendency (Mean, Median, Mode)
5.0 / 5 (0 votes)
Thanks for rating: