Biostatistics SUMMARY STEP 1 - The Basics USMLE
TLDRThe transcript discusses various medical testing scenarios, emphasizing the importance of understanding test specificity and sensitivity, positive and negative predictive values, and the difference between case-control and cohort studies. It explains how to calculate these values using 2x2 tables and how changing the cutoff point in biomarker tests affects them. The transcript also covers concepts like odds ratio, relative risk, and power of a study, concluding with an example of using standard deviation to predict cholesterol levels in patients.
Takeaways
- 📊 Understanding test specificity and sensitivity involves interpreting 2x2 tables and calculating values based on given data.
- 🧬 Differentiating between cohort and case-control studies is crucial; cohort studies follow groups over time, while case-control compares those with and without a disease.
- 🦠 In diagnostic tests, sensitivity relates to correctly identifying those with a condition (true positives), while specificity is about correctly identifying those without it (true negatives).
- 📈 When altering the cutoff value in a diagnostic test, it affects the test's sensitivity and specificity, with potential changes in false negatives and false positives.
- 🎯 The accuracy of a test is determined by its closeness to a gold standard, while precision is about the consistency of results.
- 🧪 Analyzing data involves understanding odds ratios and relative risks, which compare outcomes between different groups.
- 📉 In a scatter plot, the correlation between two variables can be positive or negative, indicating whether they increase or decrease together.
- 📚 Case fatality rate is the proportion of deaths in a specific condition, calculated by dividing the number of fatal cases by the total number of cases.
- 🔍 The power of a study refers to the probability of correctly identifying an effect when it exists, complementing the p-value which indicates the chance of observing the data by chance.
- 📈 For normally distributed data, understanding standard deviations helps predict values outside the mean, such as the number of patients with cholesterol levels above a certain threshold.
Q & A
What is the gold standard for assessing the specificity of a new test for UTIs in women?
-The gold standard for assessing the specificity of a new test for urinary tract infections (UTIs) in women is a combination of positive urine dipstick results plus urine culture results.
How is specificity calculated in the context of the provided example?
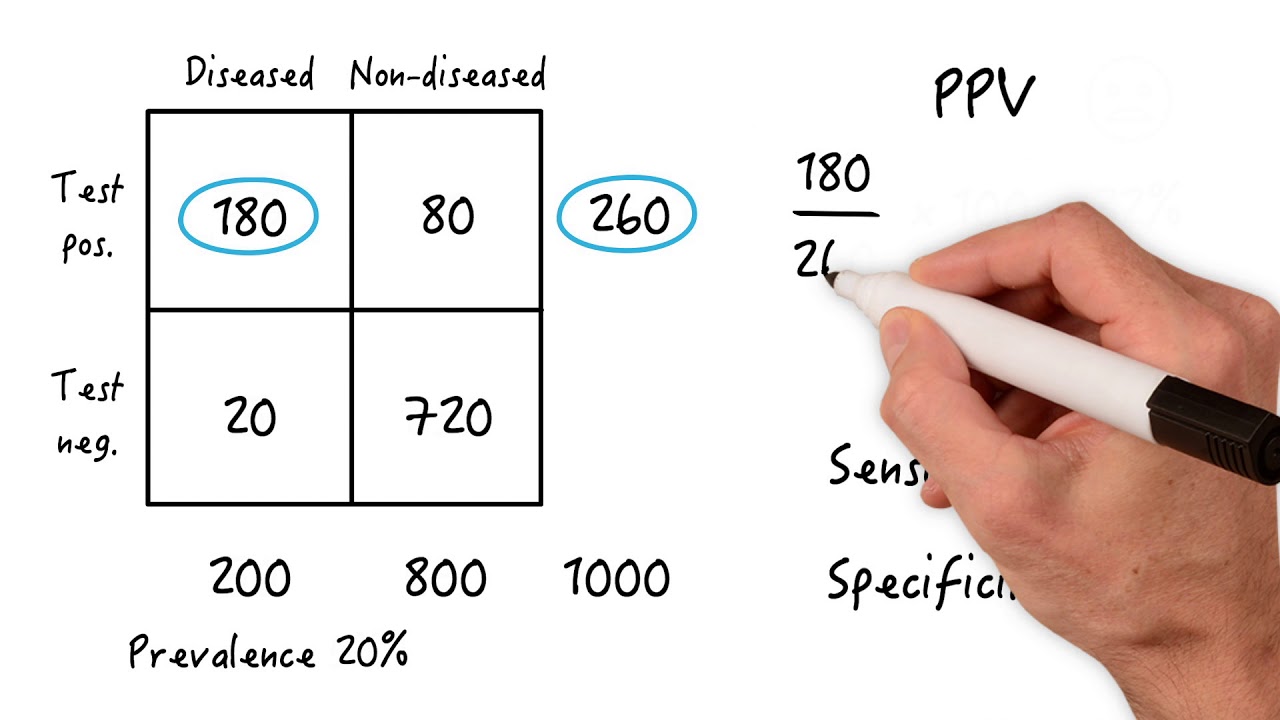
-Specificity is calculated by taking the true negatives (180) and dividing it by the sum of true negatives and false positives (180 + 20), which in the example results in a specificity of 90% (180/200).
What are the key differences between a cohort study and a case-control study?
-A cohort study follows groups of people who do and do not have a certain exposure (like pet ownership) over time to see who develops a disease. A case-control study compares people with a disease (cases) to people without the disease (controls) to identify possible risk factors.
How can you determine if a study is a cohort or case-control based on the description provided?
-If the study starts with people without the disease and follows them to see who develops it, it's a cohort study. If it compares people with and without the disease based on a known outcome, it's a case-control study.
What is the significance of relative risk and odds ratio in the context of a cohort study?
-In a cohort study, relative risk is used to compare the incidence of an outcome (like disease) between the exposed group (e.g., pet owners) and the unexposed group (non-pet owners). It is calculated as the risk of disease in the exposed group divided by the risk in the unexposed group.
How many false negatives are expected in a study with a sensitivity of 70% for a test diagnosing prostate cancer?
-In a study with 100 patients who truly have UTIs and a test sensitivity of 70%, there would be 30 false negatives, calculated as (100 - (70% of 100)) = 30.
What type of preventive measure is checking blood pressure at a health fair?
-Checking blood pressure at a health fair is an example of secondary prevention, which aims to screen for diseases early to reduce their impact.
How is the case fatality rate calculated for falls?
-The case fatality rate for falls is calculated by dividing the number of fatal falls by the total number of fall incidents. In the example, it is 4 out of 20 falls.
What can be concluded about the accuracy and precision of an instrument used to check serum levels if the standard is 40 and the readings are 70, 68, 70, 17, 75?
-The instrument is precise but not accurate. The readings are close to each other (precise), but they are not close to the gold standard of 40 (inaccurate).
What is the power of a study that has a 15% probability of concluding there is no difference in HDL measurements when there is one?
-The power of the study is 1 minus the probability of a Type II error (beta), which is 1 - 0.15, resulting in a power of 0.85 or 85%.
How can you determine the expected number of patients with cholesterol greater than 240 in a group of 200 patients with a mean cholesterol level of 210 and a standard deviation of 15?
-Expected number of patients with cholesterol greater than 240 is calculated by finding the proportion of patients beyond two standard deviations from the mean. Since 95% of values lie within two standard deviations, only 5% will be above. Therefore, in a group of 200 patients, 5% of 200 is 10 patients.
Outlines
📚 Introduction to Medical Test Analysis
The paragraph introduces a series of questions related to medical testing, emphasizing the importance of understanding the concepts of sensitivity and specificity. It explains how to approach these questions mentally, without the need for repetitive calculations, by recalling the basic formulas associated with these terms. The speaker uses an example of a test for urinary tract infections (UTIs) to illustrate how to calculate specificity, highlighting the process of interpreting a two-by-two table of test results.
🧬 Study Design and Analysis
This paragraph delves into the specifics of study design, particularly differentiating between cohort and case-control studies. It uses an example of a five-year study assessing respiratory disease in individuals over 50 years old to explain the characteristics of a cohort study. The speaker also discusses the importance of understanding the difference between relative risk and odds ratio, which are key in interpreting the results of cohort and case-control studies, respectively.
🩺 Interpreting Test Results
The speaker explains how to interpret the results of medical tests, using prostate cancer testing as an example. The paragraph focuses on understanding the concepts of false negatives and false positives, and how to calculate them based on given sensitivity and specificity values. The speaker also emphasizes the importance of creating a chart to visualize the distribution of true and false results, which aids in working backwards to solve problems related to test outcomes.
📈 Biomarker Sensitivity and Specificity
This section discusses the impact of changing the cutoff value of a biomarker on the test's sensitivity and specificity. The speaker uses a hypothetical example involving 500 healthy volunteers and 120 patients with a biomarker to illustrate how moving the cutoff point affects the number of false negatives and false positives. The paragraph explains how adjusting the cutoff value can lead to a higher negative predictive value, while cautioning that the true positives and true negatives do not change in this scenario.
📊 Understanding Distribution and Cutoff Points
The speaker explains how to determine the sensitivity of a test based on a distribution graph. Using a hypothetical scenario where a cutoff point is set to achieve 100% sensitivity, the speaker illustrates how to identify the point at which false negatives would be zero. The paragraph also discusses the impact of moving a biomarker's sensitivity curve from one point to another on the test's sensitivity and specificity, emphasizing that understanding the distribution and cutoff points is crucial for accurate test interpretation.
🏥 Medical Statistics and Prevention
This paragraph covers various statistical concepts in medical research, including case fatality rate, accuracy, precision, and the power of a study. The speaker uses examples such as spinal cord injuries and death, and the measurement of serum levels of a certain substance, to explain these concepts. The paragraph also touches on the importance of understanding primary and secondary prevention in the context of health fairs and checking blood pressure, and concludes with an explanation of relative risk in the context of prostate cancer prevalence in different groups of men.
📉 Correlation and Distribution in Medical Research
The final paragraph discusses the interpretation of scatter diagrams to determine correlation between two variables, such as alcohol consumption and test scores. The speaker explains the concept of negative and positive associations and how the slope of the line on the scatter diagram can indicate the strength of this association. Additionally, the speaker addresses a scenario involving the distribution of cholesterol levels in hospital patients with pneumonia complications, explaining how to predict the number of patients with cholesterol levels above a certain threshold based on the mean and standard deviation.
Mindmap
Keywords
💡Sensitivity
💡Specificity
💡Positive Predictive Value
💡Negative Predictive Value
💡Case-Control Study
💡Cohort Study
💡Odds Ratio
💡Relative Risk
💡Prevalence
💡Accuracy
💡Precision
Highlights
A new test for diagnosing UTIs in women is being assessed, with the gold standard being positive urine dipstick plus urine culture results.
The specificity of the test is calculated as 180 out of 200, which is 90%.
A five-year study is planned to assess the incidence and ideology of respiratory disease in 600 individuals over 50 years of age, with two groups: one that cares for a pet dog and one that does not.
The study design is a cohort study since it follows individuals who do not have the disease initially and looks for its development in the future.
In the prostate cancer study, with a sensitivity of 70 and specificity of 90, there are 30 false negatives.
The odds ratio in the study comparing older and younger students' test scores is calculated as 60 over 40 for older students and 200 over 160 for younger students.
Changing the cutoff value of a biomarker from point B to point A would most likely result in a higher negative predictive value.
The sensitivity of a test can be determined by the true positive rate over the sum of true positives and false negatives.
The specificity of a test is calculated as the true negative rate over the sum of true negatives and false positives.
When the cutoff point for a biomarker is adjusted, it affects the sensitivity and specificity of the test, with moving from right to left increasing sensitivity and moving from left to right increasing specificity.
Checking blood pressure as a health fair is an example of secondary prevention.
The case fatality rate for falls is calculated as the number of fatal falls over the total number of falls, which is 4 out of 20 in the given example.
An instrument's accuracy and precision are evaluated by comparing its readings to a gold standard and observing how closely the readings cluster together.
The p-value of a study indicates the probability that the observed results occurred by chance, with a common threshold for significance being less than 0.05.
The power of a study is the probability of correctly identifying an association when it exists, and it is calculated as one minus the probability of a type II error (beta).
Relative risk compares the risk of an outcome in one group to another, with the formula being one number over the sum of that number and the number of outcomes in the comparison group.
A scatter diagram can show the correlation between two variables, with the slope of the line indicating the direction and strength of the association.
In a normally distributed variable, the number of individuals exceeding a value more than two standard deviations above the mean can be estimated using the standard deviation and the total number of individuals.
Transcripts
Browse More Related Video





5.0 / 5 (0 votes)
Thanks for rating: