Sample Size Justification by Daniel Lakens
TLDRThis video script emphasizes the critical role of sample size in research studies, highlighting the common issue of underpowered studies with small sample sizes leading to inaccurate estimates and high type 2 error rates. It suggests moving beyond heuristics and instead using rigorous methods to determine sample size based on study goals, such as accuracy or statistical power. The speaker discusses various approaches, including a priori power analysis and sequential analysis, and stresses the importance of justifying sample size choices in light of changing academic standards and increasing journal requirements.
Takeaways
- 🔍 Importance of Sample Size: The script emphasizes the importance of considering sample size when designing a new study, as small sample sizes can lead to inaccurate estimates and high type 2 error rates.
- 📉 Historical Sample Sizes: It was common in the past to use 15 participants per between-subjects condition, but this number has increased to around 25, indicating a growing awareness of the need for larger samples.
- 📉 Effect of Sample Size on Variation: The script explains that as sample size increases, the variation in data decreases, leading to more accurate effect size estimates.
- 📊 Visualization of Sample Size Impact: The script references a visualization by Shawn blot and pillow, Guinea, which shows how the variation in data decreases with increasing sample size, illustrating the transition from 'sailing the seas of chaos' to the 'corridor of stability'.
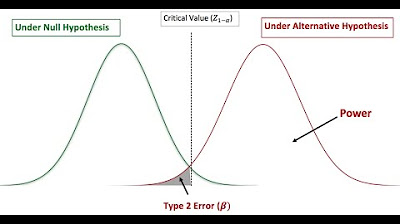
- 🧩 Problem with Small Samples: Small samples can lead to large variations and inaccurate effect size estimates, which can result in type 2 errors where true effects are not statistically significant.
- 📈 Power Failure in Studies: The script notes a power failure in studies, particularly in fields like neuroscience where sample sizes are expensive to collect, leading to underpowered studies.
- 📝 Sample Size Justification: An increasing number of journals require a sample size justification, which is a positive shift towards more rigorous study design.
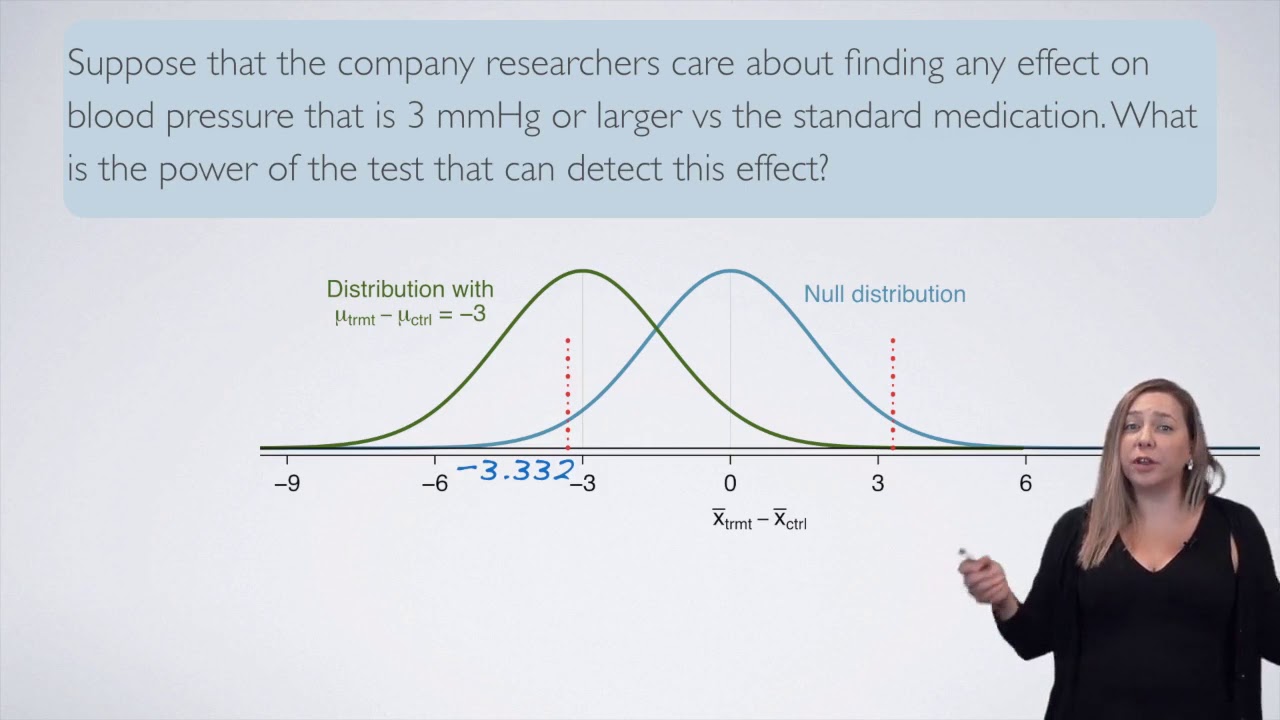
- 🎯 Goals for Sample Size: The script discusses different goals for determining sample size, such as achieving a certain accuracy or specific statistical power.
- 📚 Literature on Sample Size: It is advised to use unbiased effect size estimates for power analysis to avoid overestimation due to publication bias.
- 🔧 Feasibility Considerations: When resources are limited, it's acceptable to plan a study based on feasibility, even if it means lower statistical power.
- 📉 Bayesian Statistics: The script introduces Bayesian statistics as an alternative approach where sample size can be flexible and data collection can continue until sufficient evidence is gathered.
Q & A
Why is sample size important in designing a new study?
-Sample size is crucial because small samples can lead to large variation, resulting in inaccurate estimates and high type 2 error rates. This means that even when there is a true effect, the statistical test might not show it as significant.
What is the common heuristic for sample size in past studies?
-Historically, it was common to use a sample size of 15 participants for each between-subjects condition, but this has increased to about 25 participants in more recent times.
What are the two main issues with collecting small samples?
-Small samples can lead to large variation, making the data unstable and resulting in inaccurate effect size estimates. Additionally, they can lead to high type 2 error rates, meaning that true effects might not be statistically significant.
What is the 'corridor of stability' in the context of sample size?
-The 'corridor of stability' refers to the range of sample sizes where the variation in data becomes much less severe, leading to more accurate estimations of the true effect size.
Why have studies in certain fields, like neuroscience, been underpowered?
-Studies in fields such as neuroscience, where the cost of collecting data (e.g., using fMRI scanners) is high, often suffer from being underpowered due to the financial constraints of collecting a large sample size.
What is the current trend in academic journals regarding sample size justification?
-An increasing number of journals are requiring a sample size justification, where researchers need to explicitly state why they chose a specific sample size.
What is the average statistical power estimate in psychology studies?
-The average statistical power estimate in psychology studies is around 50 percent, meaning there is only a 50% chance of observing a statistically significant result even if the true hypothesis is correct.
What are the two main approaches to planning a study's sample size?
-The two main approaches are planning for accuracy, which involves selecting a sample size based on the desired width of a confidence interval, and planning for power, which involves selecting a sample size based on the probability of observing a statistically significant result.
What is the recommended sample size for achieving approximately 95% power in a study?
-To achieve about 95% power, it is generally recommended to have a sample size of about 100 people in each condition, depending on the effect size.
What is a sequential analysis and when is it used?
-Sequential analysis is a method where data is collected and examined as it comes in, allowing researchers to control type 1 error rates while deciding when to stop data collection. It's used when there's significant uncertainty and the goal is to achieve a statistically significant result.
How does Bayesian statistics approach sample size determination?
-Bayesian statistics allows for more flexibility in determining the sample size. Unlike frequentist approaches, it does not require specifying the sample size in advance. Instead, data collection can continue until the researcher decides to stop, quantifying the evidence in the data as it accumulates.
What is the importance of justifying the sample size in a study?
-Justifying the sample size is important because it ensures that the study is designed to be adequately powered and accurate. It also helps to prevent the design of studies that are likely to be underpowered and produce unreliable results.
Outlines
🔍 Importance of Sample Size in Research Design
The paragraph emphasizes the crucial role of sample size in research studies. It points out the common issue of small sample sizes leading to inaccurate estimates and high type 2 error rates, which can result in failing to detect true effects. The author shares personal experiences from their PhD days, highlighting the shift from using 15 to 25 participants per condition as a heuristic. The paragraph introduces a visualization by Shawn blot and pillow Guinea, illustrating how data variation decreases with increasing sample size, leading to more stable and accurate effect size estimates. The metaphor of 'sailing the seas of chaos' versus entering the 'corridor of stability' is used to describe the transition from large to small data variation. The author also discusses the historical lack of consideration for sample size in study design and the slow change towards requiring sample size justifications in journals, which is expected to improve study power and reduce the prevalence of low-powered studies.
📊 Approaches to Determining Sample Size
This paragraph delves into various approaches for determining an appropriate sample size for a study. It discusses the necessity of justifying sample size choices based on specific research goals. The author explains the concept of planning for accuracy by selecting a sample size that narrows the confidence interval, citing Maxwell and Kelley's work as a valuable resource. Another approach mentioned is designing a study with a specific statistical power, often aiming for higher than the traditional 50% to increase the likelihood of detecting true effects. The paragraph also addresses the challenges of performing power analysis, especially when relying on potentially inflated effect sizes from published literature due to publication bias. It suggests being conservative and considering other factors beyond power analysis, such as feasibility, when resources are limited. The author introduces the idea of sequential analysis and Bayesian statistics as alternative methods for determining sample size, especially when there is significant uncertainty or when resources are constrained.
📈 The Evolution of Sample Size Justification
The final paragraph discusses the increasing importance of justifying sample size in research studies. It contrasts the past practice of conducting underpowered and inaccurate studies with the future need for a change towards more rigorous study design. The author highlights the growing requirement by journals for sample size justification, indicating a shift towards more transparency and thoughtful consideration of sample size in research. The paragraph concludes by emphasizing the significance of sample size in study design and encourages researchers not to overlook this critical aspect, aligning with the overall message of the script to prioritize and carefully consider sample size in research planning.
Mindmap
Keywords
💡Sample Size
💡Type 2 Error
💡Effect Size
💡Statistical Power
💡Hypothesis Testing
💡Confidence Interval
💡Heuristics
💡Power Analysis
💡Publication Bias
💡Feasibility
💡Bayesian Statistics
Highlights
Importance of determining an appropriate sample size for a study.
Common practice of using heuristics like 15 participants per condition is outdated.
Increased sample sizes to around 25 participants per condition are now more common.
Small sample sizes lead to large variation and inaccurate estimates.
High type 2 error rates with small samples can miss true effects.
Visualization of data variation decreasing with larger sample sizes.
Term 'sailing the seas of chaos' used to describe the unreliability of small sample sizes.
The 'corridor of stability' represents more accurate estimations with larger samples.
Historic failure to consider sample size in study design, slowly changing.
Sample size justifications are increasingly required by journals.
Psychology studies often have low statistical power, averaging around 50%.
Heuristics are unreliable for designing studies and determining sample sizes.
Planning for accuracy by selecting sample size based on confidence interval width.
Designing studies for specific statistical power, such as 95%.
The necessity of a priori power analysis based on expected effect size.
Potentially large sample sizes required for substantial power.
Care needed in using effect sizes from published literature due to publication bias.
Sequential analysis as an alternative to a priori power analysis.
Planning for feasibility when resources are limited.
Bayesian statistics offer flexibility in determining sample size.
The increasing importance of justifying sample size in study design.
Transcripts
Browse More Related Video




5.0 / 5 (0 votes)
Thanks for rating: